Nếu bạn từng thắc mắc tại sao các website lớn như Google, Facebook hay các ngân hàng hiếm khi “sập” dù có hàng triệu người truy cập cùng lúc, câu trả lời nằm ở một khái niệm gọi là High Availability. Đây là nền tảng giúp các hệ thống công nghệ hiện đại duy trì hoạt động liên tục, ngay cả khi có sự cố xảy ra phía sau. Bài viết này sẽ giúp bạn hiểu rõ High Availability là gì, cách đo lường, nguyên lý vận hành và những thách thức thực tế khi triển khai.
High Availability (HA) là gì?
High Availability là đặc tính của một hệ thống công nghệ thông tin được thiết kế để hoạt động ổn định và có thể truy cập được trong một khoảng thời gian dài, với mức độ gián đoạn gần như bằng không.
Nói một cách dễ hiểu, một hệ thống có High Availability là hệ thống mà người dùng luôn có thể sử dụng được, bất kể đang là giờ cao điểm, ngày lễ hay thời điểm nào trong năm.
Tuy nhiên cần lưu ý một điểm quan trọng: High Availability không đồng nghĩa với việc hệ thống không bao giờ gặp lỗi. Trên thực tế, lỗi phần cứng, lỗi phần mềm hay sự cố mạng vẫn có thể xảy ra bất cứ lúc nào. Bản chất của HA là khả năng tự động khôi phục hoặc chuyển đổi sang thành phần dự phòng ngay khi sự cố xuất hiện, sao cho người dùng cuối hầu như không cảm nhận được rằng hệ thống vừa gặp vấn đề.
Có thể hình dung HA giống như một dàn diễn viên dự bị trong một buổi biểu diễn trực tiếp. Nếu diễn viên chính gặp sự cố giữa chương trình, diễn viên dự bị sẽ lập tức bước lên thay thế. Khán giả vẫn xem được buổi diễn trọn vẹn, dù phía sau sân khấu vừa có một sự cố được xử lý kịp thời.

Hiểu về con số “99.999%” (The Five Nines)
Khi tìm hiểu về High Availability, bạn sẽ thường gặp các con số như 99.9%, 99.99% hay 99.999%. Đây chính là chỉ số Uptime, được dùng để đo lường mức độ sẵn sàng của một hệ thống.
Uptime được tính bằng tỷ lệ phần trăm thời gian hệ thống hoạt động bình thường so với tổng thời gian trong một khoảng thời gian nhất định, thường là một năm. Phần thời gian còn lại, khi hệ thống ngừng hoạt động hoặc không thể truy cập, được gọi là Downtime.
Điều thú vị là chỉ cần thêm một chữ số 9 vào sau dấu phẩy, thời gian downtime cho phép sẽ giảm đi đáng kể. Bảng dưới đây thể hiện rõ sự khác biệt này:
| Uptime | Thời gian downtime tối đa trong 1 năm |
| 99.9% (3 số 9) | ~8.76 giờ |
| 99.99% (4 số 9) | ~52.56 phút |
| 99.999% (5 số 9) | ~5.26 phút |
Nhìn vào bảng trên có thể thấy, để đạt mức “Five Nines” tức 99.999%, toàn bộ hệ thống trong cả một năm chỉ được phép gián đoạn tổng cộng hơn 5 phút. Đây là tiêu chuẩn vàng mà nhiều hệ thống tài chính, viễn thông và hạ tầng quan trọng hướng tới.
Mức độ quan trọng của những con số này không chỉ nằm trên lý thuyết. Theo báo cáo “Hidden Costs of Downtime” của Splunk và Cisco năm 2026, tổng thiệt hại do downtime trên toàn cầu đối với nhóm doanh nghiệp Global 2000 đã lên tới 600 tỷ USD mỗi năm, tăng đáng kể so với mức 400 tỷ USD của hai năm trước đó. Cũng theo khảo sát của ITIC, 93% tổ chức cho biết chỉ một giờ downtime đã gây thiệt hại hơn 300.000 USD. Những con số này cho thấy vì sao việc đầu tư vào High Availability không phải là một lựa chọn xa xỉ, mà là một yêu cầu sống còn với nhiều doanh nghiệp.

Nguyên lý cốt lõi để xây dựng hệ thống High Availability
Để một hệ thống đạt được tính sẵn sàng cao, các kỹ sư hạ tầng thường tuân theo bốn nguyên lý nền tảng sau đây.
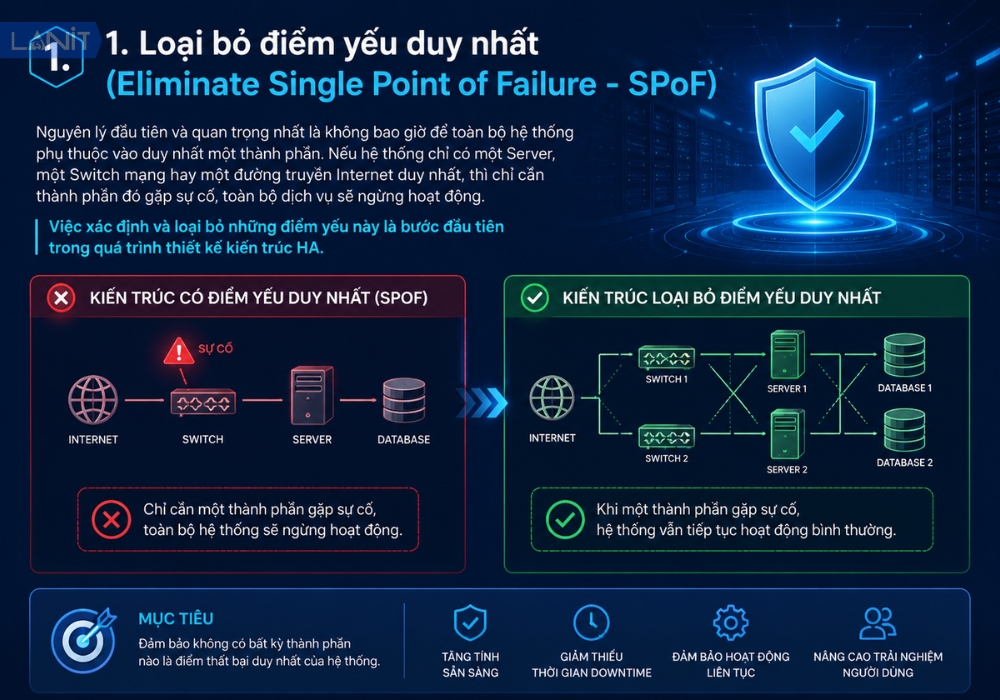
1. Loại bỏ điểm yếu duy nhất (Eliminate Single Point of Failure – SPoF)
Nguyên lý đầu tiên và quan trọng nhất là không bao giờ để toàn bộ hệ thống phụ thuộc vào duy nhất một thành phần. Nếu hệ thống chỉ có một Server, một Switch mạng hay một đường truyền Internet duy nhất, thì chỉ cần thành phần đó gặp sự cố, toàn bộ dịch vụ sẽ ngừng hoạt động. Việc xác định và loại bỏ những điểm yếu này là bước đầu tiên trong quá trình thiết kế kiến trúc HA.
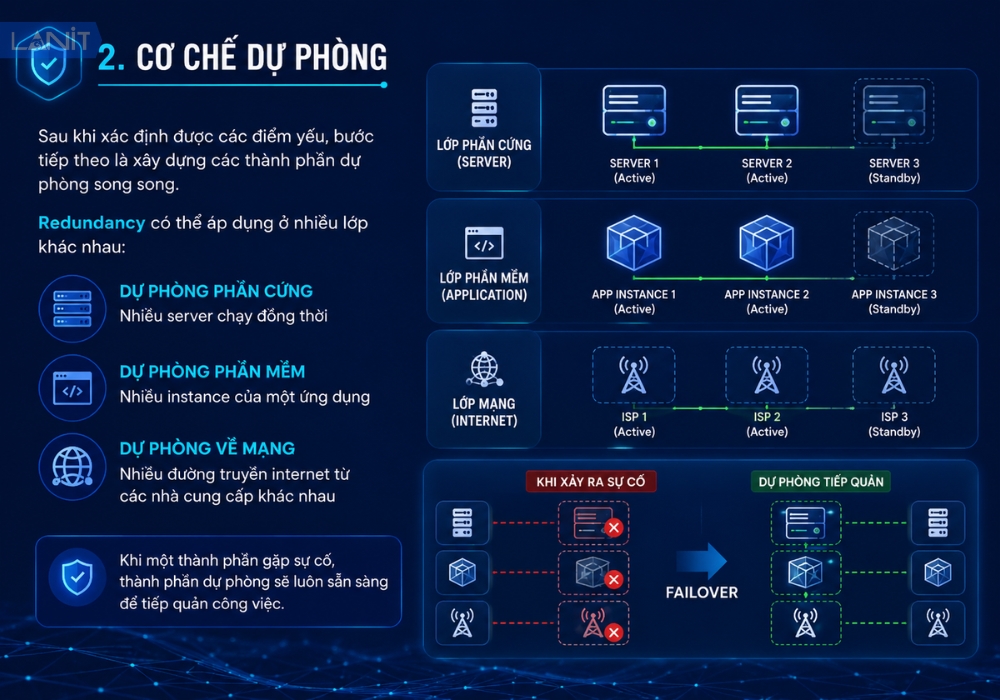
2. Cơ chế dự phòng
Sau khi xác định được các điểm yếu, bước tiếp theo là xây dựng các thành phần dự phòng song song. Redundancy có thể áp dụng ở nhiều lớp khác nhau: dự phòng phần cứng như nhiều server chạy đồng thời, dự phòng phần mềm như nhiều instance của một ứng dụng, và dự phòng về mạng như nhiều đường truyền internet từ các nhà cung cấp khác nhau. Khi một thành phần gặp sự cố, thành phần dự phòng sẽ luôn sẵn sàng để tiếp quản công việc.
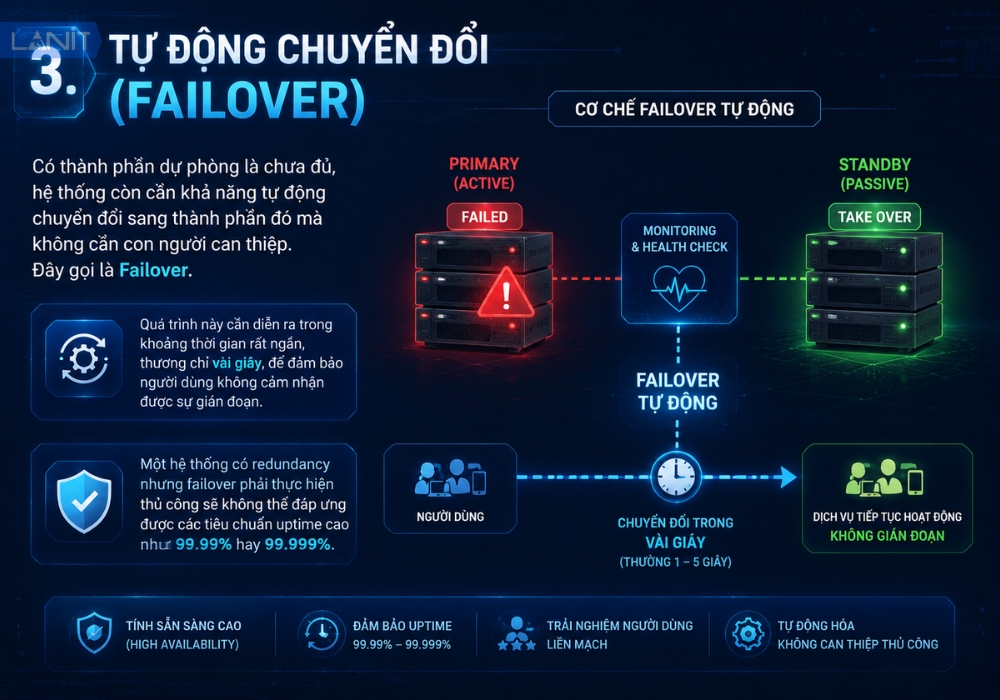
3. Tự động chuyển đổi (Failover)
Có thành phần dự phòng là chưa đủ, hệ thống còn cần khả năng tự động chuyển đổi sang thành phần đó mà không cần con người can thiệp. Đây gọi là Failover. Quá trình này cần diễn ra trong khoảng thời gian rất ngắn, thường chỉ vài giây, để đảm bảo người dùng không cảm nhận được sự gián đoạn. Một hệ thống có redundancy nhưng failover phải thực hiện thủ công sẽ không thể đáp ứng được các tiêu chuẩn uptime cao như 99.99% hay 99.999%.
4. Giám sát chủ động (Monitoring)
Nguyên lý cuối cùng nhưng không kém phần quan trọng là khả năng giám sát liên tục. Hệ thống cần biết chính xác thời điểm một thành phần bắt đầu gặp lỗi để có thể kích hoạt quá trình failover kịp thời. Nếu không có cơ chế giám sát chủ động, sự cố có thể tồn tại trong một khoảng thời gian dài trước khi được phát hiện, làm mất đi toàn bộ ý nghĩa của việc xây dựng các thành phần dự phòng.

Phân biệt: High Availability vs. Fault Tolerance vs. Disaster Recovery
Đây là một trong những điểm dễ gây nhầm lẫn nhất khi tìm hiểu về tính sẵn sàng cao, bởi ba khái niệm này thường được sử dụng lẫn nhau dù bản chất khác biệt rõ ràng.
High Availability ưu tiên giảm thiểu thời gian Downtime xuống mức tối thiểu, nhưng vẫn chấp nhận có thể tồn tại một khoảng gián đoạn cực ngắn, thường chỉ vài giây, trong quá trình chuyển đổi giữa các thành phần. Đây là giải pháp cân bằng giữa chi phí và hiệu quả, phù hợp với phần lớn hệ thống doanh nghiệp.
Fault Tolerance là cấp độ cao hơn, nơi hệ thống vẫn tiếp tục hoạt động hoàn toàn bình thường ngay cả khi một phần cứng bị hỏng, tức Zero Downtime tuyệt đối. Để đạt được điều này, các thành phần phần cứng phải chạy song song và đồng bộ theo thời gian thực ở mức độ rất sâu. Chính vì yêu cầu kỹ thuật khắt khe như vậy, chi phí đầu tư cho Fault Tolerance thường cực kỳ đắt đỏ và chỉ phù hợp với các hệ thống đặc biệt quan trọng như điều khiển hàng không hay giao dịch tài chính tốc độ cao.
Disaster Recovery, thường viết tắt là DR, lại giải quyết một bài toán hoàn toàn khác. Đây là kế hoạch khôi phục hệ thống sau những thảm họa quy mô lớn như động đất, hỏa hoạn tại trung tâm dữ liệu hoặc các sự cố nghiêm trọng làm tê liệt toàn bộ một khu vực hạ tầng. DR thường được xem là một cấp độ bảo vệ cao hơn và bổ sung cho HA, tập trung vào việc đảm bảo doanh nghiệp có thể phục hồi hoạt động dù trung tâm dữ liệu chính bị phá hủy hoàn toàn.
Có thể tóm gọn sự khác biệt: HA giải quyết các sự cố thường gặp trong vận hành hàng ngày, Fault Tolerance loại bỏ hoàn toàn downtime với chi phí rất cao, còn Disaster Recovery chuẩn bị cho những tình huống thảm họa hiếm gặp nhưng có thể gây thiệt hại toàn diện.

Các chỉ số đo lường HA (KPIs)
Khi đánh giá hoặc thiết kế một hệ thống High Availability, hai chỉ số sau đây luôn được nhắc đến như những tiêu chuẩn cốt lõi.
- RTO, viết tắt của Recovery Time Objective, là khoảng thời gian tối đa mà doanh nghiệp cho phép hệ thống ngừng hoạt động để tiến hành khôi phục. Ví dụ nếu RTO được đặt ra là 15 phút, điều đó có nghĩa là kể từ lúc xảy ra sự cố, hệ thống phải được khôi phục hoàn toàn trong vòng 15 phút.
- RPO, viết tắt của Recovery Point Objective, lại đo lường một khía cạnh khác: lượng dữ liệu tối đa có thể bị mất tính từ lần backup gần nhất. Nếu RPO là 1 giờ, điều đó đồng nghĩa với việc trong trường hợp xấu nhất, doanh nghiệp có thể mất dữ liệu phát sinh trong vòng 1 giờ trước khi sự cố xảy ra.
Hai chỉ số này thường đi cùng nhau khi xây dựng chiến lược HA và DR, vì chúng phản ánh hai khía cạnh quan trọng nhất mà bất kỳ doanh nghiệp nào cũng cần cân nhắc: thời gian gián đoạn dịch vụ và mức độ rủi ro mất dữ liệu.

Các kiến trúc HA phổ biến
Trên thực tế, có nhiều mô hình kiến trúc khác nhau được áp dụng để hiện thực hóa các nguyên lý High Availability đã nêu ở trên.
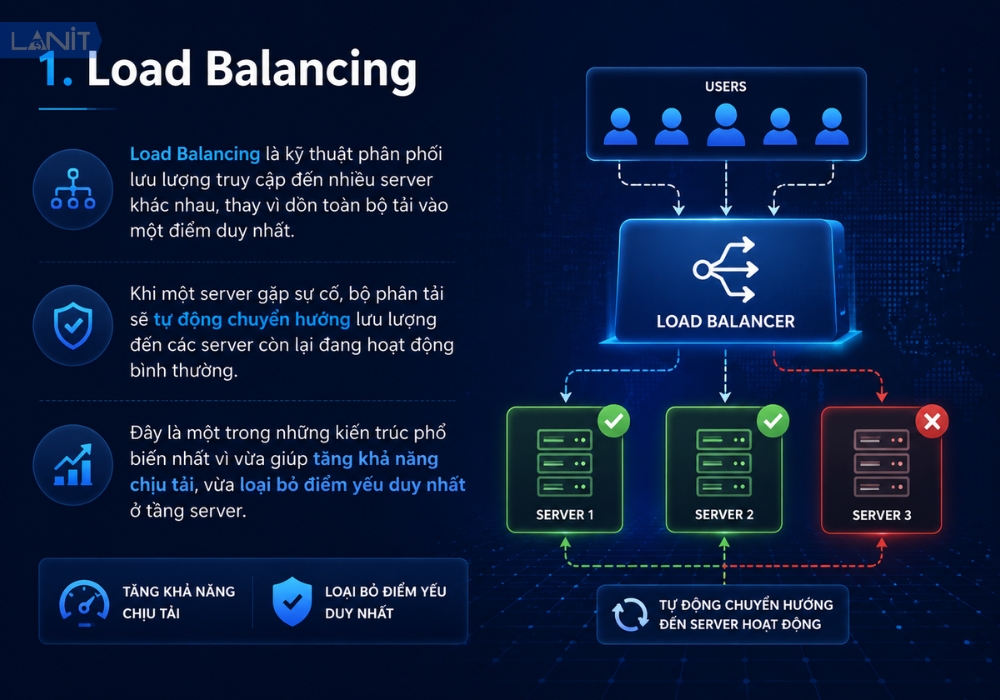
1. Load Balancing
Load Balancing là kỹ thuật phân phối lưu lượng truy cập đến nhiều server khác nhau, thay vì dồn toàn bộ tải vào một điểm duy nhất. Khi một server gặp sự cố, bộ phân tải sẽ tự động chuyển hướng lưu lượng đến các server còn lại đang hoạt động bình thường. Đây là một trong những kiến trúc phổ biến nhất vì vừa giúp tăng khả năng chịu tải, vừa loại bỏ điểm yếu duy nhất ở tầng server.
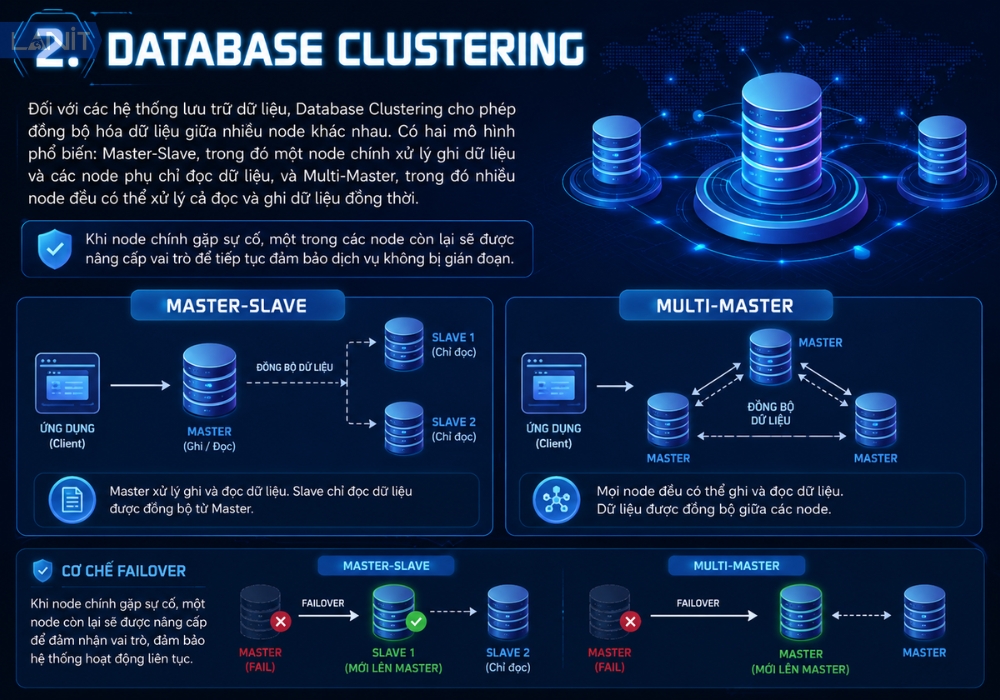
2. Database Clustering
Đối với các hệ thống lưu trữ dữ liệu, Database Clustering cho phép đồng bộ hóa dữ liệu giữa nhiều node khác nhau. Có hai mô hình phổ biến: Master-Slave, trong đó một node chính xử lý ghi dữ liệu và các node phụ chỉ đọc dữ liệu, và Multi-Master, trong đó nhiều node đều có thể xử lý cả đọc và ghi dữ liệu đồng thời. Khi node chính gặp sự cố, một trong các node còn lại sẽ được nâng cấp vai trò để tiếp tục đảm bảo dịch vụ không bị gián đoạn.
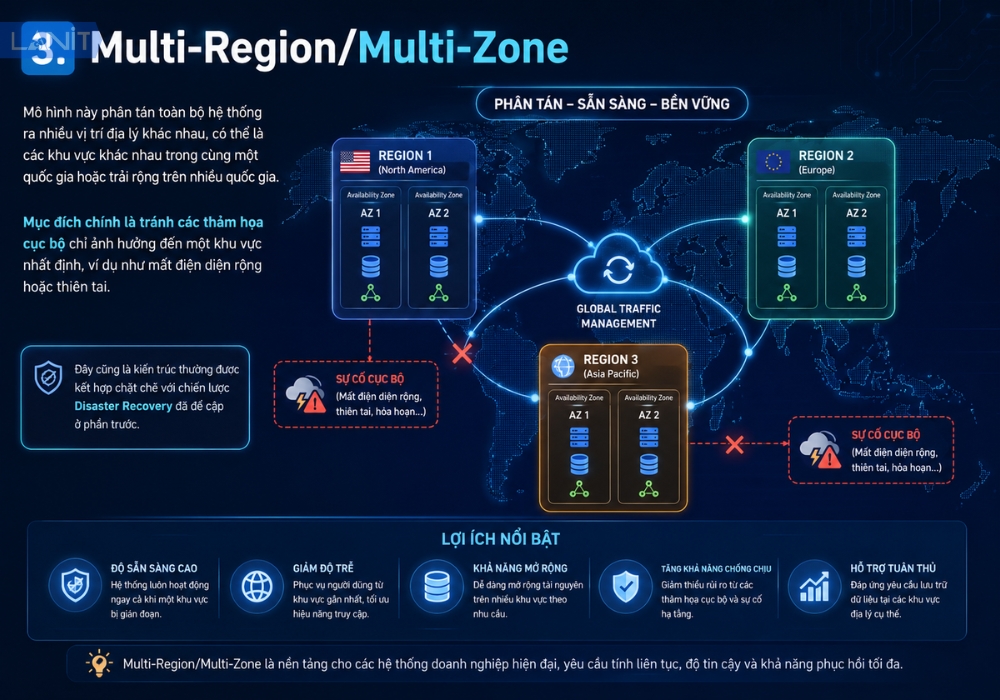
3. Multi-Region/Multi-Zone
Mô hình này phân tán toàn bộ hệ thống ra nhiều vị trí địa lý khác nhau, có thể là các khu vực khác nhau trong cùng một quốc gia hoặc trải rộng trên nhiều quốc gia. Mục đích chính là tránh các thảm họa cục bộ chỉ ảnh hưởng đến một khu vực nhất định, ví dụ như mất điện diện rộng hoặc thiên tai. Đây cũng là kiến trúc thường được kết hợp chặt chẽ với chiến lược Disaster Recovery đã đề cập ở phần trước.
Thách thức khi triển khai hệ thống HA
Mặc dù mang lại nhiều lợi ích, việc xây dựng một hệ thống High Availability không phải là điều đơn giản và đi kèm với không ít thách thức thực tế.
- Chi phí đầu tư và vận hành đắt đỏ: Việc triển khai hệ thống HA đòi hỏi doanh nghiệp phải đầu tư gấp đôi hoặc gấp ba lần hạ tầng phần cứng và phần mềm so với hệ thống thông thường để xây dựng các thành phần dự phòng (Redundancy). Ngân sách này không chỉ dừng lại ở chi phí mua sắm ban đầu mà còn bao gồm các khoản chi phí liên tục cho việc bảo trì, cập nhật công nghệ và quản lý hạ tầng ổn định trong suốt vòng đời của hệ thống.
- Độ phức tạp trong quản lý và kiểm thử kỹ thuật: Để hệ thống vận hành đúng như mong đợi, đội ngũ kỹ thuật phải giải quyết các bài toán khó như: đồng bộ dữ liệu thời gian thực giữa các node dự phòng, cấu hình chính xác cơ chế Failover để chuyển đổi tự động khi có sự cố, và thực hiện kiểm thử định kỳ. Nếu thiếu các kịch bản kiểm thử nghiêm ngặt, hệ thống HA có thể thất bại đúng vào thời điểm cần sự tin cậy cao nhất.
- Rào cản về chuyên môn nhân sự: Việc vận hành một hệ thống có cấu trúc phức tạp đòi hỏi đội ngũ kỹ thuật phải có tay nghề cao, am hiểu sâu rộng về hạ tầng mạng và quản trị cơ sở dữ liệu. Đối với các doanh nghiệp vừa và nhỏ (SMEs), đây thường là bài toán khó nhất, vì việc xây dựng và duy trì một đội ngũ vận hành chuyên trách chuyên nghiệp đòi hỏi nguồn lực rất lớn, vượt quá khả năng hiện tại của nhiều đơn vị.

High Availability là một trong những yếu tố nền tảng quyết định sự ổn định và uy tín của bất kỳ hệ thống công nghệ thông tin nào trong thời đại số. Hiểu rõ High Availability là gì, cùng các nguyên lý như loại bỏ điểm yếu duy nhất, xây dựng cơ chế dự phòng, tự động chuyển đổi và giám sát chủ động, sẽ giúp doanh nghiệp đưa ra những quyết định đầu tư hạ tầng phù hợp với quy mô và ngân sách thực tế của mình. Dù không phải hệ thống nào cũng cần đạt đến mức “Five Nines”, việc cân nhắc giữa chi phí, độ phức tạp và mức độ sẵn sàng cần thiết vẫn luôn là bài toán quan trọng mà mọi tổ chức cần giải quyết trước khi xây dựng hạ tầng của mình.