Server đang chạy bình thường hay bạn chỉ nghĩ vậy? Hàng nghìn doanh nghiệp mỗi năm chịu thiệt hại vì downtime không được phát hiện kịp thời, CPU spike âm thầm kéo tụt hiệu năng, hay một container bị memory leak chạy suốt đêm mà không ai hay. Monitoring Cloud VPS không phải tùy chọn, đó là lớp bảo vệ bắt buộc cho bất kỳ hạ tầng cloud nào muốn vận hành ổn định và tiết kiệm chi phí thực sự.
Cloud Monitoring là gì?
Cloud Monitoring (giám sát đám mây) là tập hợp các quy trình, công cụ và kỹ thuật được sử dụng để theo dõi, thu thập và phân tích dữ liệu hiệu năng của hạ tầng cloud theo thời gian thực. Đối với môi trường Cloud VPS, điều này bao gồm việc giám sát liên tục các chỉ số như CPU usage, RAM, Disk I/O, Bandwidth, Latency và Uptime.
Khác với monitoring truyền thống trên máy chủ vật lý, Cloud Monitoring hoạt động theo mô hình phân tán . Điều này cho phép đội ngũ kỹ thuật quan sát toàn bộ hệ thống từ một điểm duy nhất.
Monitoring Cloud VPS không dừng lại ở việc “xem số liệu”. Hệ thống tốt phải có khả năng cảnh báo tự động (alerting), phân tích xu hướng (trend analysis) và hỗ trợ chẩn đoán sự cố (incident diagnosis) nhanh chóng trước khi người dùng cuối bị ảnh hưởng.

Tầm quan trọng của Cloud Monitoring
Một hệ thống cloud không được giám sát là một hệ thống đang chờ sự cố xảy ra. Với đặc thù của môi trường cloud, một điểm thất bại nhỏ có thể lan rộng thành sự cố toàn hệ thống chỉ trong vài phút.
Uptime là tài sản vô hình nhưng có giá trị đo lường được. Theo nghiên cứu của Gartner, mỗi phút downtime của hạ tầng doanh nghiệp có thể tiêu tốn từ vài trăm đến hàng nghìn USD tùy quy mô. Monitoring Cloud VPS giúp rút ngắn MTTD và MTTR, hai chỉ số quan trọng nhất
Với Developer, monitoring cung cấp dữ liệu cần thiết để tối ưu code, phát hiện memory leak, và lập kế hoạch Scalability. Với chủ doanh nghiệp, đây là công cụ kiểm soát chi phí hạ tầng, tránh việc trả tiền cho tài nguyên không được sử dụng hoặc thiếu tài nguyên vào đúng thời điểm tải cao.
Tính năng chính của Cloud Monitoring
Giám sát tài nguyên hệ thống
Đây là tầng cơ bản nhất, theo dõi các chỉ số:
- CPU Usage: phát hiện spike bất thường, process chiếm tài nguyên quá mức
- RAM / Memory: theo dõi memory leak, thiếu bộ nhớ gây swap
- Disk I/O: đo lường tốc độ đọc/ghi, phát hiện bottleneck lưu trữ
- Network Bandwidth & Latency: kiểm soát lưu lượng, phát hiện DDoS hoặc traffic bất thường

Giám sát ứng dụng
APM theo dõi hiệu năng ở tầng ứng dụng: response time của API, số lượng request per second (RPS), error rate, và transaction tracing. Đây là lớp quan trọng để Developer xác định đúng nguyên nhân gốc rễ của vấn đề hiệu năng.
Alerting & Notification
Hệ thống cảnh báo cho phép thiết lập ngưỡng (threshold) cho từng chỉ số. Khi CPU vượt 85% liên tục 5 phút, hoặc Disk I/O đạt giới hạn, cảnh báo được gửi qua email, Slack, PagerDuty hoặc webhook. Alerting hiệu quả phải có khả năng phân biệt cảnh báo thật với nhiễu (alert fatigue).
Log Management và phân tích
Thu thập và lưu trữ log từ hệ thống, ứng dụng và security events. Công cụ như ELK Stack (Elasticsearch, Logstash, Kibana) hoặc Grafana Loki cho phép tìm kiếm log theo thời gian thực và tương quan sự kiện với dữ liệu metric.

Dashboard & Visualization
Biểu đồ thời gian thực tổng hợp dữ liệu từ nhiều nguồn, giúp cả Developer lẫn quản lý không chuyên kỹ thuật đọc hiểu tình trạng hệ thống chỉ trong vài giây.
Lợi ích của Cloud Monitoring
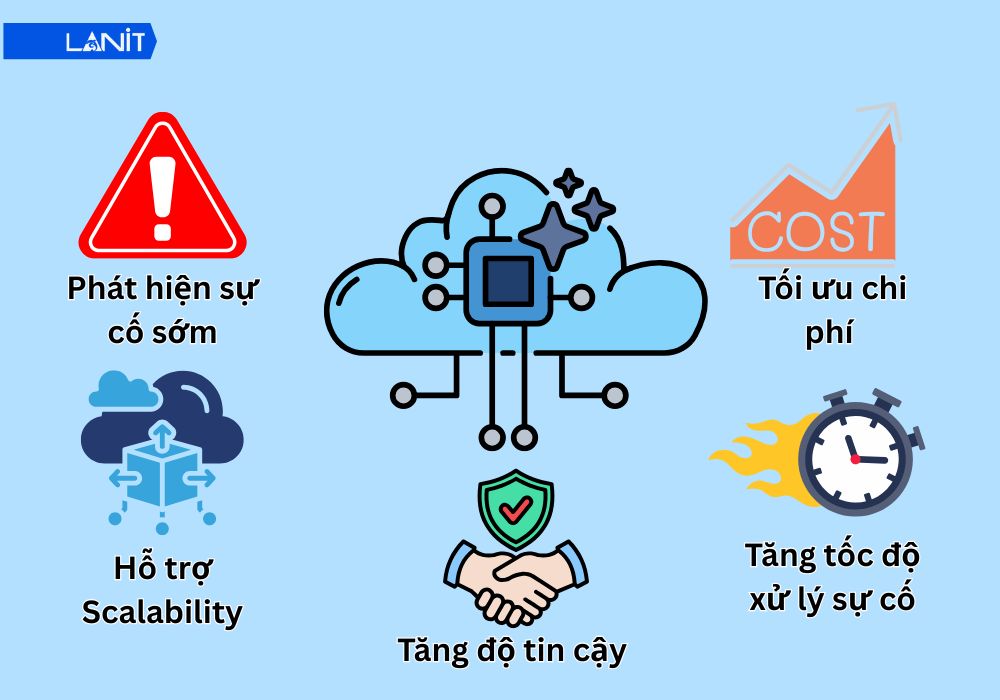
- Phát hiện sự cố trước khi người dùng biết: Monitoring chủ động (proactive monitoring) cho phép phát hiện dấu hiệu bất thường sớm. Ví dụ Disk usage tăng dần đều và can thiệp trước khi hệ thống đạt ngưỡng nguy hiểm.
- Tối ưu chi phí hạ tầng: Dữ liệu lịch sử giúp xác định đúng mức tài nguyên cần thiết. Thay vì provision VPS theo cảm tính, doanh nghiệp có thể right-size tài nguyên dựa trên dữ liệu thực tế tránh lãng phí hoặc thiếu hụt.
- Hỗ trợ Scalability có kế hoạch: Xu hướng tăng trưởng tải được phát hiện từ sớm, cho phép lên kế hoạch mở rộng hạ tầng đúng thời điểm thay vì phản ứng khẩn cấp khi hệ thống đã quá tải.
- Tăng độ tin cậy với khách hàng: SLA (Service Level Agreement) được bảo đảm khi có dữ liệu Uptime minh bạch. Doanh nghiệp có thể cam kết Uptime 99.9% với bằng chứng đo lường cụ thể.
- Tăng tốc độ xử lý sự cố: Khi có incident, đội kỹ thuật không mất thời gian phỏng đoán, dữ liệu metric và log được tương quan tự động, rút ngắn MTTR từ hàng giờ xuống còn vài phút.
So sánh các loại Cloud Monitoring
| Loại Monitoring | Phạm vi giám sát | Công cụ phổ biến | Phù hợp với |
| Infrastructure Monitoring | CPU, RAM, Disk, Network | Zabbix, Nagios, Datadog | SysAdmin, DevOps |
| Application Performance Monitoring (APM) | Response time, Error rate, Transaction | New Relic, AppDynamics, Elastic APM | Developer |
| Log Monitoring | System log, App log, Security log | ELK Stack, Splunk, Grafana Loki | Security, DevOps |
| Network Monitoring | Bandwidth, Latency, Packet loss | PRTG, SolarWinds, Wireshark | Network Engineer |
| Synthetic Monitoring | Uptime, Availability từ nhiều địa điểm | UptimeRobot, Pingdom, Checkly | Developer, QA |
| Database Monitoring | Query performance, Connection pool, Slow query | pgBadger, Percona Monitoring | DBA, Developer |
Cloud-based vs On-premises Monitoring
Lựa chọn giữa giải pháp monitoring trên nền cloud và giải pháp tự triển khai (on-premises) phụ thuộc vào quy mô, ngân sách và yêu cầu kiểm soát dữ liệu của tổ chức.
| Tiêu chí | Cloud-based Monitoring | On-premises Monitoring |
| Chi phí ban đầu | Thấp (pay-as-you-go) | Cao (hạ tầng, license) |
| Chi phí vận hành | Dự đoán được theo subscription | Phụ thuộc đội ngũ nội bộ |
| Thời gian triển khai | Nhanh (vài giờ đến vài ngày) | Chậm (vài tuần đến vài tháng) |
| Scalability | Tự động, linh hoạt | Giới hạn bởi phần cứng |
| Kiểm soát dữ liệu | Phụ thuộc nhà cung cấp | Toàn quyền kiểm soát |
| Bảo mật / Compliance | Phụ thuộc SLA nhà cung cấp | Tự kiểm soát hoàn toàn |
| Yêu cầu kỹ thuật nội bộ | Thấp | Cao |
Các nhà cung cấp Cloud Monitoring
Giải pháp thương mại (SaaS)
- Datadog: Nền tảng monitoring toàn diện, mạnh về APM và tích hợp với hơn 500 dịch vụ. Phù hợp cho doanh nghiệp có hạ tầng phức tạp. Chi phí cao, nhưng ROI rõ ràng ở quy mô lớn.
- New Relic: Chuyên sâu về APM, hỗ trợ tốt nhiều ngôn ngữ lập trình (Java, Python, Node.js, Go). Giao diện trực quan, phù hợp cho Developer team.
- Grafana Cloud: Kết hợp Grafana visualization với Prometheus metrics và Loki log management. Có tier miễn phí, linh hoạt cao, phổ biến trong cộng đồng open-source.
- Amazon CloudWatch: Tích hợp sẵn với AWS ecosystem. Lựa chọn tự nhiên nếu hạ tầng chạy trên AWS.
Giải pháp Open-source
- Zabbix: Giải pháp enterprise open-source mạnh mẽ, hỗ trợ SNMP, agent-based và agentless monitoring. Phù hợp với môi trường có nhiều server cần kiểm soát chi tiết.
- Prometheus + Grafana: Bộ đôi phổ biến nhất trong cộng đồng DevOps. Prometheus thu thập và lưu trữ metric dạng time-series; Grafana hiển thị dashboard. Không có chi phí license, nhưng đòi hỏi kiến thức triển khai và vận hành.
Các bước triển khai Cloud Monitoring
Bước 1: Xác định phạm vi và mục tiêu monitoring
Trước khi cài bất kỳ công cụ nào, cần trả lời: Cần giám sát cái gì? Vì mục đích gì? Liệt kê toàn bộ các thành phần hạ tầng (VPS instances, database, load balancer, CDN) và xác định chỉ số quan trọng nhất với từng thành phần.
Bước 2: Chọn công cụ phù hợp
Dựa trên phạm vi đã xác định, ngân sách và năng lực kỹ thuật nội bộ, chọn giải pháp phù hợp. Không cần dùng công cụ đắt tiền nhất, cần dùng công cụ phù hợp nhất với bài toán hiện tại.
Bước 3: Cài đặt agent và cấu hình thu thập dữ liệu
bash
# Cài đặt Node Exporter trên VPS Ubuntu/Debian để thu thập system metrics
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
tar xvfz node_exporter-1.7.0.linux-amd64.tar.gz
cd node_exporter-1.7.0.linux-amd64
# Chạy như systemd service
sudo cp node_exporter /usr/local/bin/
sudo useradd --no-create-home --shell /bin/false node_exporter
sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter
# Tạo systemd service file
sudo tee /etc/systemd/system/node_exporter.service > /dev/null <<EOF
[Unit]
Description=Node Exporter
After=network.target
[Service]
User=node_exporter
Group=node_exporter
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl enable node_exporterBước 4: Thiết lập dashboard và alert rules
Tạo dashboard theo nhóm chức năng: một dashboard cho infrastructure overview, một cho application performance, một cho security events. Thiết lập alert rules với ngưỡng rõ ràng:
yaml
# Ví dụ alert rule trong Prometheus (alerting rules)
groups:
- name: vps_alerts
rules:
- alert: HighCPUUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 5m
labels:
severity: warning
annotations:
summary: "CPU usage cao trên {{ $labels.instance }}"
description: "CPU usage: {{ $value }}% trong 5 phút liên tiếp"
- alert: DiskSpaceLow
expr: (node_filesystem_avail_bytes / node_filesystem_size_bytes) * 100 < 15
for: 2m
labels:
severity: critical
annotations:
summary: "Disk space thấp trên {{ $labels.instance }}"Bước 5: Kiểm thử và tối ưu hệ thống cảnh báo
Chạy thử các kịch bản sự cố giả lập (load test, fill disk) để kiểm tra alert có kích hoạt đúng không. Điều chỉnh ngưỡng để giảm false positive — alert quá nhiều sẽ khiến đội ngũ mất cảnh giác (alert fatigue). Xây dựng runbook cho từng loại cảnh báo để rút ngắn thời gian xử lý.
Bước 6: Thiết lập quy trình review định kỳ
Monitoring không phải cấu hình một lần rồi bỏ. Hạ tầng thay đổi, ứng dụng cập nhật — cấu hình monitoring cần được review ít nhất mỗi quý. Đặt lịch review monthly metric trends để phát hiện sớm các vấn đề tăng trưởng tài nguyên.
Monitoring Cloud VPS hiệu quả là sự kết hợp giữa công cụ phù hợp, cấu hình đúng và quy trình vận hành rõ ràng. Không có hệ thống nào là bất khả xâm phạm — nhưng hệ thống được giám sát tốt sẽ luôn phục hồi nhanh hơn, thiệt hại ít hơn và chi phí vận hành thấp hơn về dài hạn.








![[Kinh Nghiệm] Mua Hosting Cho Blog Wordpress Cực Chi Tiết](https://lanit.com.vn/wp-content/uploads/2023/12/blog-website-wp.jpg)