Trong các hệ thống máy chủ, mạng và cơ sở dữ liệu hiện đại, việc duy trì hoạt động liên tục là yếu tố sống còn đối với doanh nghiệp. Đây chính là lúc cơ chế Failover phát huy vai trò quan trọng. Vậy Failover là gì, hoạt động theo nguyên lý nào và khi nào cần triển khai? Bài viết dưới đây sẽ giải đáp chi tiết.
Failover là gì?
Failover là một cơ chế trong hệ thống máy tính và mạng, cho phép tự động chuyển quyền điều khiển và xử lý tác vụ từ một thành phần đang gặp sự cố (Server, Database, Network) sang một thành phần dự phòng (Standby) đã ở trạng thái sẵn sàng.
Mục tiêu chính của Failover là đảm bảo hệ thống đạt được tính sẵn sàng cao (High Availability – HA), từ đó giảm thiểu tối đa thời gian Downtime (thời gian hệ thống ngừng hoạt động). Đối với các doanh nghiệp vận hành dịch vụ trực tuyến, mỗi phút Downtime đều có thể gây thiệt hại về doanh thu và uy tín, vì vậy Failover được xem là một thành phần không thể thiếu trong kiến trúc hạ tầng hiện đại.

Cơ chế hoạt động của Failover
Để hiểu rõ Failover là gì trong thực tế vận hành, cần nắm được quy trình kỹ thuật phía sau. Một hệ thống Failover thường hoạt động theo bốn bước cơ bản sau:
1. Heartbeat (Nhịp Tim)
Server chính và Server dự phòng liên tục trao đổi các gói tin nhỏ gọi là Heartbeat qua một kênh kết nối riêng (thường là một đường mạng vật lý hoặc logic độc lập với đường truyền dữ liệu chính, gọi là Heartbeat Link), nhằm tránh trường hợp đường truyền chính bị nghẽn làm sai lệch kết quả giám sát.
Chu kỳ gửi tín hiệu (interval) thường được cấu hình trong khoảng vài trăm milliseconds đến vài giây, tùy theo yêu cầu về tốc độ phản ứng của hệ thống. Một số công nghệ phổ biến sử dụng cơ chế này gồm VRRP cho thiết bị mạng, Pacemaker/Corosync trong các cụm Linux HA, hoặc cơ chế heartbeat riêng của WSFC.
Mỗi gói Heartbeat thường mang thông tin trạng thái như CPU, bộ nhớ hoặc tình trạng dịch vụ, giúp Server dự phòng không chỉ biết “còn sống” mà còn biết Server chính có đang vận hành ổn định hay không.

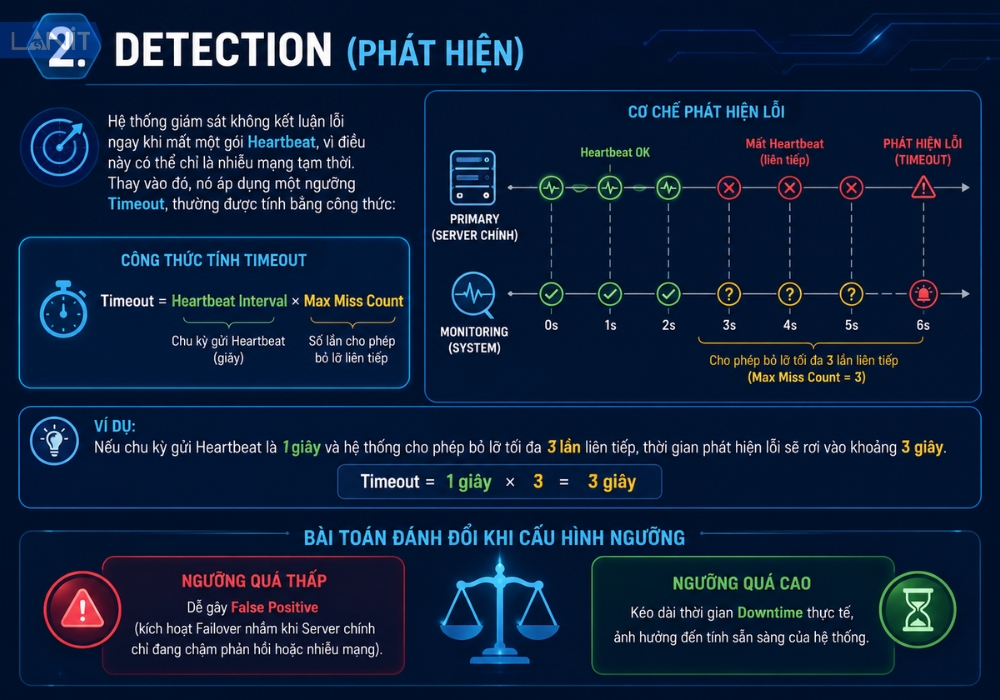
2. Detection (Phát Hiện)
Hệ thống giám sát không kết luận lỗi ngay khi mất một gói Heartbeat, vì điều này có thể chỉ là nhiễu mạng tạm thời. Thay vào đó, nó áp dụng một ngưỡng Timeout, thường được tính bằng công thức:
Ví dụ, nếu chu kỳ gửi Heartbeat là 1 giây và hệ thống cho phép bỏ lỡ tối đa 3 lần liên tiếp, thời gian phát hiện lỗi sẽ rơi vào khoảng 3 giây. Việc cấu hình ngưỡng này là một bài toán đánh đổi: ngưỡng quá thấp dễ gây False Positive (kích hoạt Failover nhầm khi Server chính chỉ đang chậm phản hồi), còn ngưỡng quá cao sẽ kéo dài thời gian Downtime thực tế.
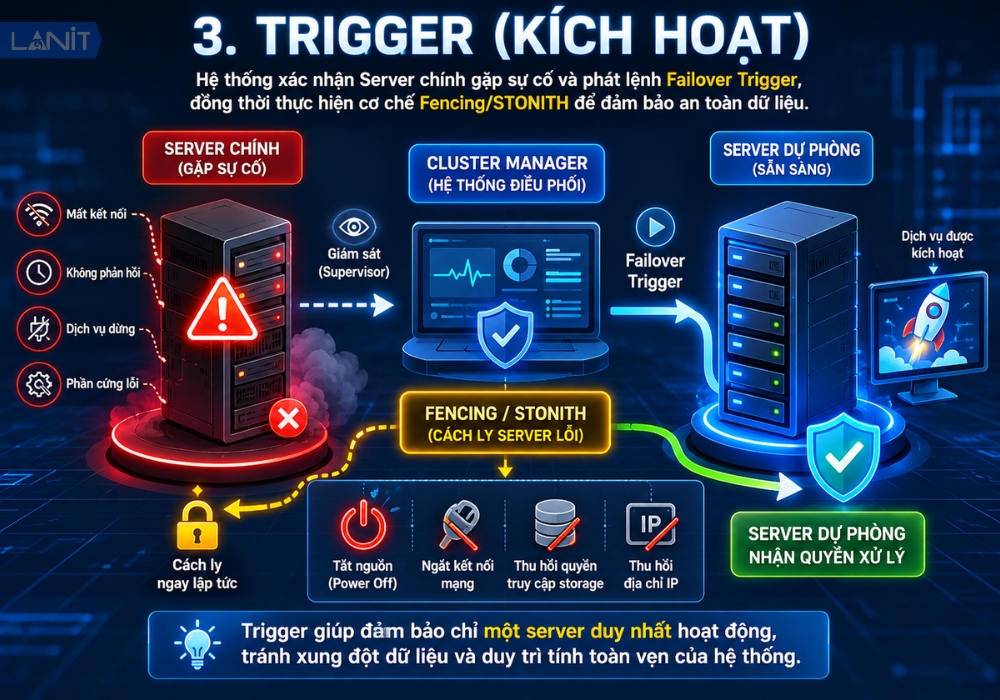
3. Trigger (Kích Hoạt)
Khi đã xác nhận Server chính gặp sự cố, hệ thống điều phối (thường là một Cluster Manager hoặc phần mềm giám sát chuyên dụng) sẽ phát lệnh Failover Trigger. Tại bước này, hệ thống thường thực hiện thêm cơ chế Fencing hoặc STONITH, tức là cách ly hoặc buộc tắt hoàn toàn Server gặp lỗi trước khi trao quyền cho Server dự phòng. Bước cách ly này rất quan trọng để đảm bảo Server cũ không bất ngờ hoạt động trở lại và cùng xử lý dữ liệu song song với Server mới, gây ra xung đột.
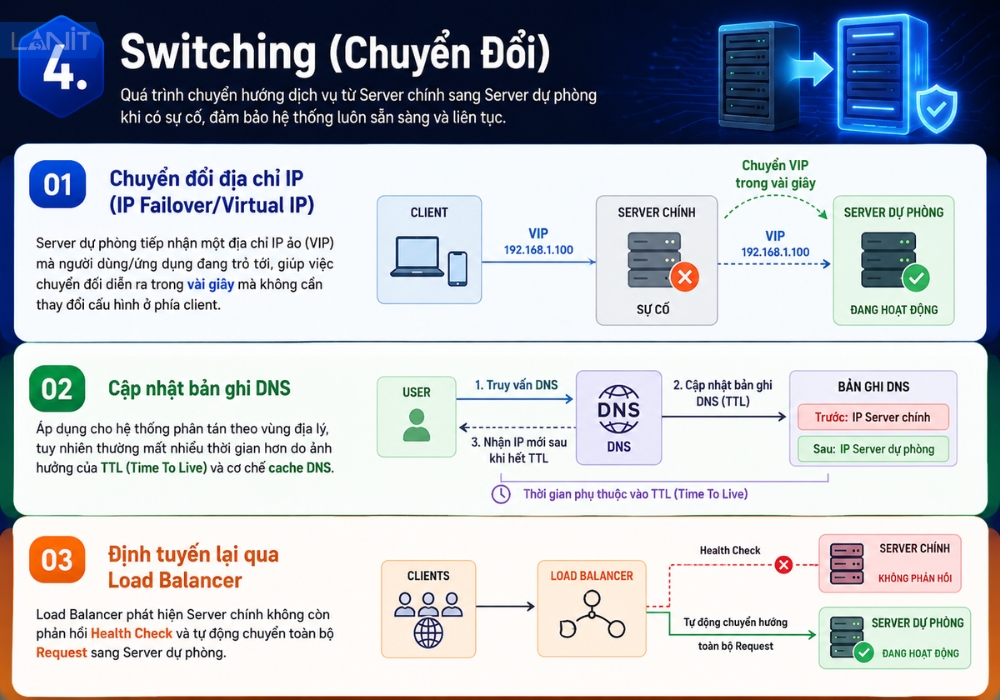
4. Switching (Chuyển Đổi)
Sau khi trigger được xác nhận an toàn, hệ thống tiến hành điều hướng lưu lượng sang Server dự phòng thông qua một hoặc kết hợp nhiều phương thức:
- Chuyển đổi địa chỉ IP (IP Failover/Virtual IP): Server dự phòng tiếp nhận một địa chỉ IP ảo (VIP) mà người dùng/ứng dụng đang trỏ tới, giúp việc chuyển đổi diễn ra trong vài giây mà không cần thay đổi cấu hình ở phía client.
- Cập nhật bản ghi DNS: Áp dụng cho hệ thống phân tán theo vùng địa lý, tuy nhiên thường mất nhiều thời gian hơn do ảnh hưởng của TTL (Time To Live) và cơ chế cache DNS.
- Định tuyến lại qua Load Balancer: Load Balancer phát hiện Server chính không còn phản hồi Health Check và tự động chuyển toàn bộ Request sang Server dự phòng.
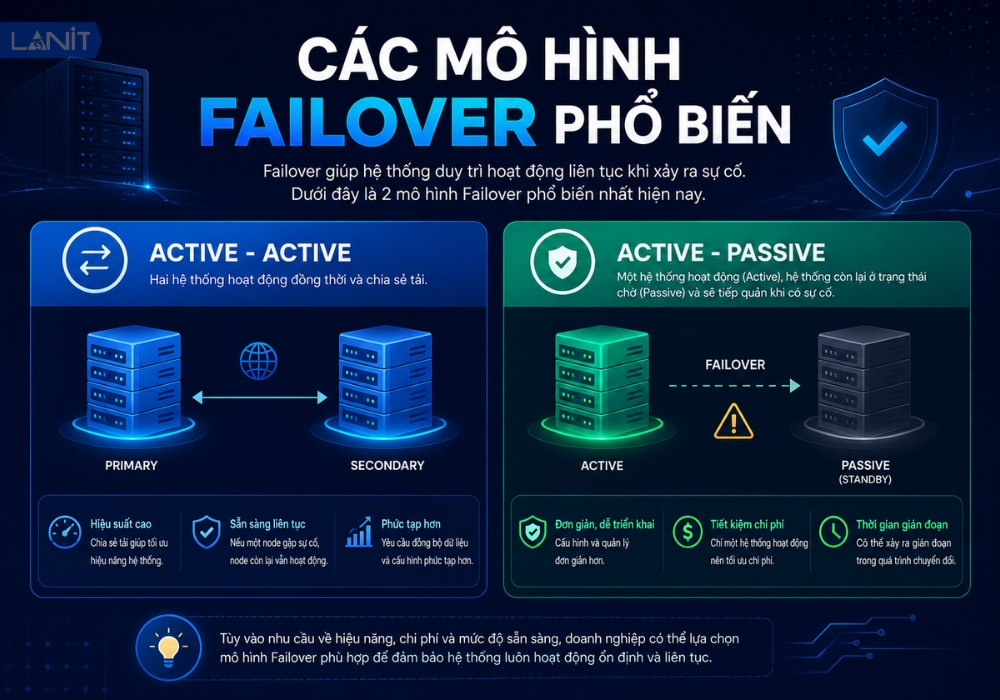
Các mô hình Failover phổ biến
Hiện nay có hai mô hình Failover được triển khai phổ biến nhất, mỗi mô hình phù hợp với những nhu cầu và ngân sách khác nhau.
| Mô hình | Đặc điểm | Ưu điểm | Nhược điểm |
| Active-Passive | Một Server chạy chính, một Server chờ ở trạng thái Standby. | Tiết kiệm tài nguyên, dễ triển khai. | Mất thời gian chuyển đổi (Failover time), có thể gây gián đoạn ngắn. |
| Active-Active | Cả hai Server cùng hoạt động và chia sẻ tải xử lý. | Hiệu năng cao, chuyển đổi gần như tức thì. | Cấu hình phức tạp, chi phí đầu tư cao hơn. |
Việc lựa chọn mô hình nào phụ thuộc vào yêu cầu về thời gian phục hồi, ngân sách hạ tầng và mức độ quan trọng của hệ thống.
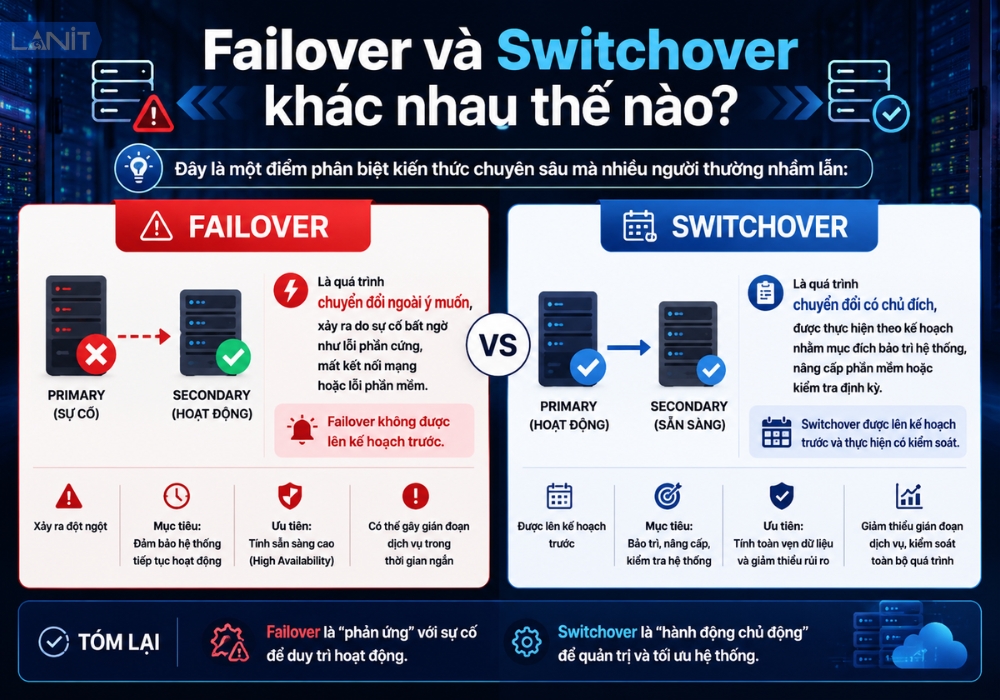
Failover và Switchover khác nhau thế nào?
Đây là một điểm phân biệt kiến thức chuyên sâu mà nhiều người thường nhầm lẫn:
- Failover: Là quá trình chuyển đổi ngoài ý muốn, xảy ra do sự cố bất ngờ như lỗi phần cứng, mất kết nối mạng hoặc lỗi phần mềm. Failover không được lên kế hoạch trước.
- Switchover: Là quá trình chuyển đổi có chủ đích, được thực hiện theo kế hoạch nhằm mục đích bảo trì hệ thống, nâng cấp phần mềm hoặc kiểm tra định kỳ.
Những thách thức khi triển khai Failover
Mặc dù mang lại nhiều lợi ích, việc triển khai Failover trong thực tế cũng đi kèm không ít thách thức kỹ thuật.
1. Split-brain Syndrome (Hội Chứng Não Phân Tách)
Đây là tình huống cả Server chính và Server dự phòng đều “tưởng” mình là Server chính tại cùng một thời điểm, dẫn đến xung đột dữ liệu nghiêm trọng. Tình huống này thường xảy ra khi kết nối giám sát giữa hai Server bị đứt nhưng cả hai vẫn hoạt động độc lập.
Khi một máy chủ trong hệ thống gặp sự cố, để đảm bảo dữ liệu không bị hỏng, hệ thống sẽ sử dụng hai cơ chế bảo vệ là Quorum và Fencing:
- Quorum (Quy tắc đa số): Các node còn lại “họp bàn” với nhau. Chỉ khi chiếm đa số, chúng mới được phép tiếp tục làm việc. Nếu không đủ số lượng (mất Quorum), hệ thống sẽ tự dừng để đảm bảo an toàn.
- Fencing (Cách ly): Sau khi đã xác định được node lỗi, hệ thống sẽ thực hiện “cắt đuôi” bằng cách ngắt kết nối vật lý (điện hoặc mạng) của node đó, ngăn không cho nó tiếp tục ghi dữ liệu vào ổ đĩa chung.

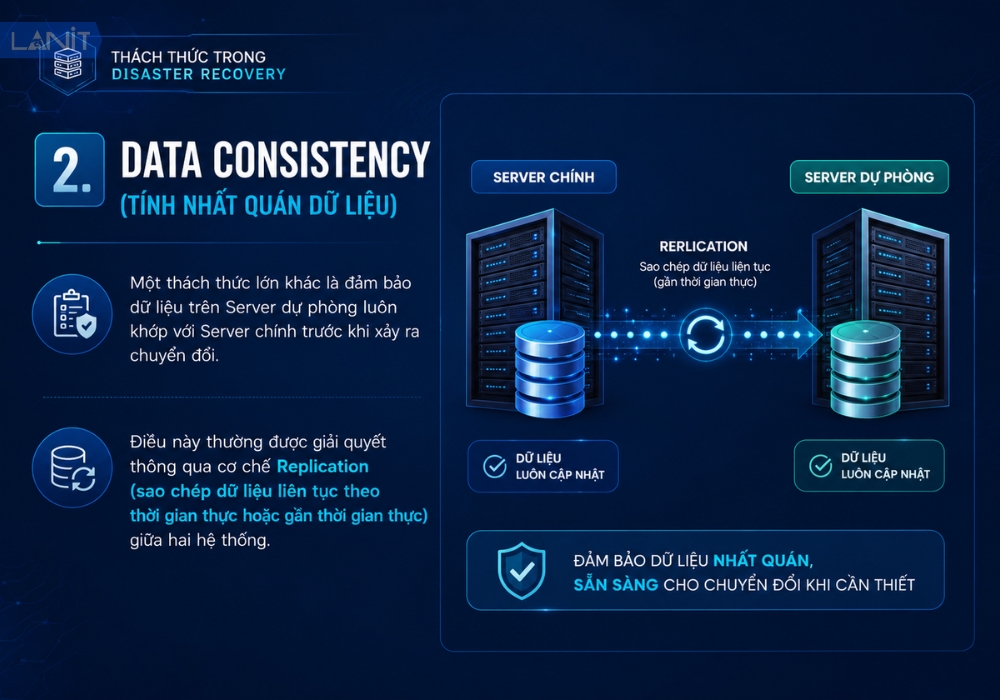
2. Data Consistency (Tính nhất quán dữ liệu)
Một thách thức lớn khác là đảm bảo dữ liệu trên Server dự phòng luôn khớp với Server chính trước khi xảy ra chuyển đổi. Điều này thường được giải quyết thông qua cơ chế Replication (sao chép dữ liệu liên tục theo thời gian thực hoặc gần thời gian thực) giữa hai hệ thống.
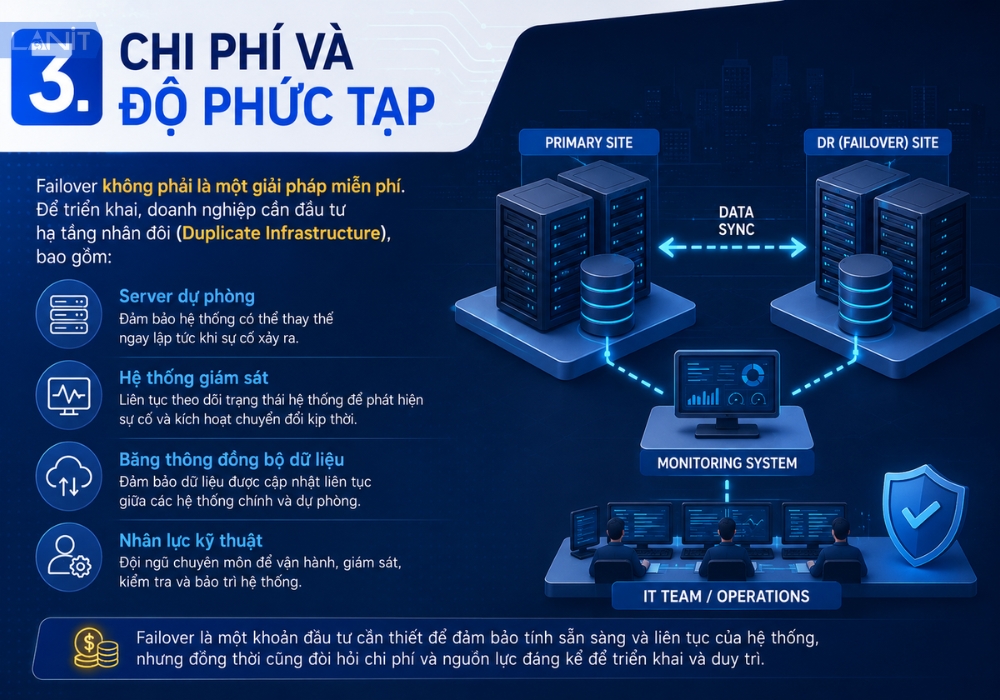
3. Chi phí và độ phức tạp
Failover không phải là một giải pháp miễn phí. Để triển khai, doanh nghiệp cần đầu tư hạ tầng nhân đôi (Duplicate Infrastructure), bao gồm Server dự phòng, hệ thống giám sát, băng thông đồng bộ dữ liệu, cũng như nhân lực kỹ thuật để vận hành và bảo trì.
Khi nào cần triển khai Failover?
Failover thường được triển khai trong các trường hợp sau:
- Hệ thống Database: SQL Server, MySQL, MongoDB và các hệ quản trị cơ sở dữ liệu cần đảm bảo dữ liệu luôn truy cập được.
- Hệ thống Web Server/Load Balancer: Đảm bảo website hoặc ứng dụng luôn trực tuyến với người dùng.
- Hệ thống mạng doanh nghiệp: Firewall, Router và các thiết bị hạ tầng mạng cốt lõi.
- Ứng dụng yêu cầu uptime cao: Các lĩnh vực như E-commerce, Fintech thường yêu cầu mức uptime 99.99% trở lên, nơi mà bất kỳ downtime nào cũng gây thiệt hại trực tiếp đến doanh thu và trải nghiệm khách hàng.

Câu hỏi thường gặp
Failover là một trong những cơ chế then chốt đảm bảo hệ thống luôn sẵn sàng ngay cả khi phần cứng hoặc mạng gặp sự cố. Dưới đây là giải đáp chi tiết cho những thắc mắc thường gặp xung quanh quá trình chuyển đổi dự phòng này:
Failover có gây mất dữ liệu không?
Mức độ mất dữ liệu (nếu có) được đo bằng chỉ số RPO – khoảng thời gian dữ liệu có thể bị mất tính từ lần sao lưu/đồng bộ gần nhất. Thời gian để hệ thống phục hồi hoàn toàn được đo bằng RTO. Nếu hệ thống đồng bộ dữ liệu tốt (RPO thấp), khả năng mất dữ liệu khi Failover sẽ được giảm thiểu đáng kể, nhưng không phải lúc nào cũng bằng 0%.
Failover có tự động 100% không?
Không hoàn toàn. Mức độ tự động của Failover phụ thuộc vào cấu hình triển khai:
- Automatic Failover: Hệ thống tự động phát hiện lỗi và chuyển đổi mà không cần con người can thiệp.
- Manual Failover: Cần quản trị viên xác nhận và thực hiện lệnh chuyển đổi thủ công sau khi phát hiện sự cố.
Nhiều tổ chức lựa chọn kết hợp cả hai hình thức để vừa đảm bảo tốc độ phản ứng, vừa tránh các trường hợp chuyển đổi nhầm do lỗi giám sát.
Sự khác biệt giữa Failover và Load Balancing?
Load Balancing là cơ chế phân chia lưu lượng truy cập đồng đều giữa nhiều Server đang hoạt động cùng lúc, nhằm mục đích tối ưu hiệu năng và tránh quá tải. Trong khi đó, Failover tập trung vào việc duy trì tính sẵn sàng của hệ thống khi có sự cố xảy ra, bằng cách chuyển tác vụ sang thành phần dự phòng.
Trên thực tế, hai cơ chế này thường được triển khai song song: Load Balancing giúp tối ưu hiệu suất trong điều kiện vận hành bình thường, còn Failover đảm bảo hệ thống vẫn hoạt động khi gặp sự cố.