Trong kỷ nguyên của trí tuệ nhân tạo, OpenClaw đã khẳng định vị thế là một trong những mô hình ngôn ngữ mạnh mẽ nhất, giúp doanh nghiệp đột phá về hiệu suất. Tuy nhiên, đi kèm với năng lực xử lý ấn tượng là bài toán về chi phí vận hành. Làm thế nào để tận dụng tối đa sức mạnh của OpenClaw mà không khiến ngân sách “vượt ngưỡng”? Bài viết này sẽ đi sâu vào các chiến lược tối ưu hóa cấu trúc dữ liệu đầu vào và quản lý token hiệu quả để giúp bạn đạt được điểm cân bằng hoàn hảo giữa chi phí và chất lượng.
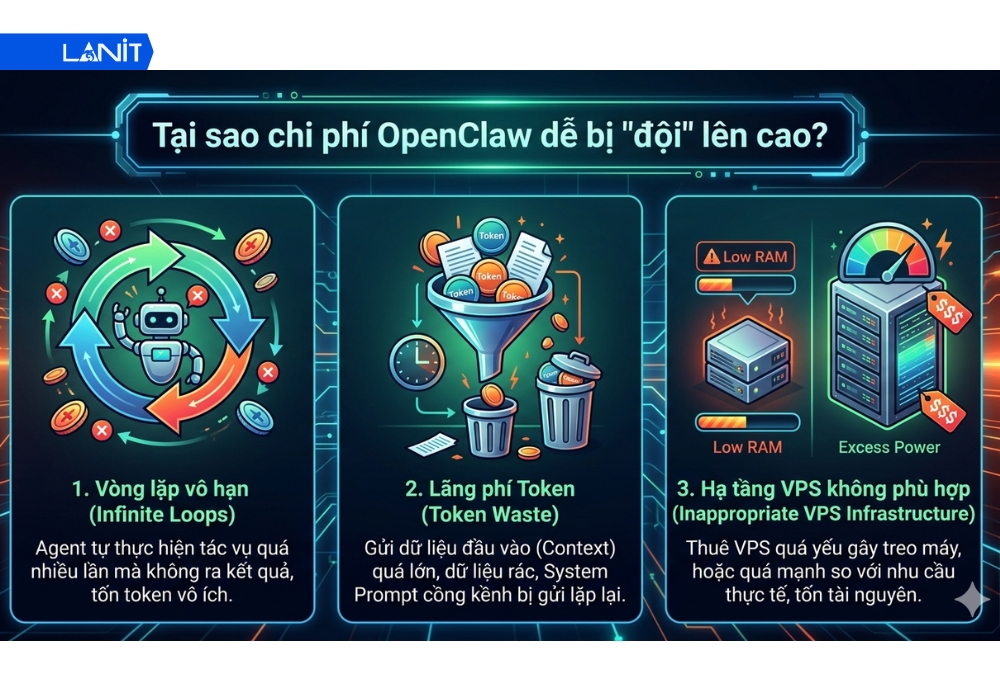
Tại sao chi phí OpenClaw dễ bị “đội” lên cao?
Với các phiên bản AI Agent hiện nay, OpenClaw giống như một động cơ phản lực đầy uy lực nhưng cũng cực kì “ngốn” nhiên liệu nếu không được quản lý đúng cách. Nhiều người dùng lầm tưởng rằng chi phí chỉ đến từ những câu hỏi của họ, nhưng thực tế, phần lớn ngân sách thường bị “đốt” sạch bởi những lỗ hổng trong cấu hình bối cảnh và sự thiếu kiểm soát trong luồng vận hành của Agent.
- Vòng lặp vô hạn (Infinite Loops): Khi Agent gặp một tác vụ khó hoặc lỗi phần mềm, nó có thể tự động thử lại (retry) liên tục. Mỗi lần thử lại là một lần gửi yêu cầu lên server AI. Nếu không có điểm dừng, Agent sẽ tiêu tốn token liên tục mà không đưa ra được kết quả cuối cùng.
- Lãng phí Token: Token chính là tiền. Việc lãng phí token thường đến từ:
- Tích tụ bối cảnh (Context Accumulation): Chiếm tới 40-50% tổng chi phí. OpenClaw có cơ chế gửi lại toàn bộ lịch sử hội thoại. Đến lượt chat thứ 10, bạn đang phải trả tiền để gửi đi nội dung của 9 lượt trước đó.
- Dữ liệu rác: Khi Agent đọc một file log quá lớn hoặc tìm kiếm web, nó “nhét” tất cả vào bộ nhớ bối cảnh, khiến lượng dữ liệu gửi đi tăng theo cấp số nhân.
- System Prompt cồng kềnh: Những tệp hướng dẫn như SOUL.md hay AGENTS.md thường rất nặng (5K-10K token). Nếu không tối ưu, mỗi câu hỏi ngắn của bạn cũng phải “cõng” theo cả một tệp hướng dẫn khổng lồ.
- Hạ tầng không phù hợp: Việc chọn sai cấu hình máy chủ (VPS) cũng khiến bạn mất tiền oan
- VPS quá yếu (<2GB RAM): Gây treo máy, làm gián đoạn công việc và buộc Agent phải chạy lại từ đầu, gây tốn token.
- VPS quá mạnh: Thuê một gói 50-70 USD/tháng trong khi nhu cầu thực tế chỉ cần gói 5-10 USD/tháng là một sự lãng phí tài nguyên nghiêm trọng.
Hướng dẫn mẹo tối ưu chi phí khi sử dụng OpenClaw
Để kiểm soát tốt chi phí, chúng ta cần tối ưu đồng bộ trên 4 tầng chính: API & LLM, hạ tầng Server, logic vận hành và mô hình mã nguồn mở. Dưới đây là các giải pháp cụ thể:
1. Tối ưu tầng API và Mô hình ngôn ngữ (LLM)
Nguyên tắc vàng để tối ưu tài chính không phải là chọn mô hình rẻ nhất, mà là chọn mô hình “đúng việc” nhất. Việc sử dụng những siêu mẫu như Claude 3.5 Sonnet hay GPT-4o cho các tác vụ phân loại văn bản đơn giản là một sự lãng phí xa xỉ. Một chiến lược thông minh tại tầng API sẽ giúp bạn phân phối khối lượng công việc linh hoạt, giữ cho bộ não AI luôn nhạy bén mà vẫn bảo vệ được số dư tài khoản của bạn.
- Mô hình giá rẻ (GPT-4o-mini, Gemini Flash, Haiku): Dùng cho 80% tác vụ nhẹ như phân loại yêu cầu, tóm tắt nội dung hoặc kiểm tra trạng thái (heartbeat).
- Mô hình cao cấp (Sonnet 3.5, GPT-4o): Chỉ kích hoạt khi cần tư duy logic phức tạp hoặc viết code khó.
*Kết quả: Chỉ riêng việc dùng Haiku thay vì các bản Pro/Opus cho tác vụ nền đã giúp bạn tiết kiệm 50-80% chi phí ngay lập tức.
Ngoài ra, hãy luôn nhớ:
- Cấu hình max_output_tokens từ 1.500 – 2.000 để tránh AI “nói dài, nói dai” gây tốn tiền.
- Bật tính năng Prompt Caching (enablePromptCaching: true). Tính năng này giúp lưu bộ nhớ đệm cho các chỉ dẫn hệ thống tĩnh, giảm tới 90% chi phí bối cảnh lặp lại.
*Mẹo thực chiến: Sử dụng Router thông minh để tự động chuyển model theo loại task, kết hợp JSON Mode + Structured Output để output luôn gọn gàng và đúng format.
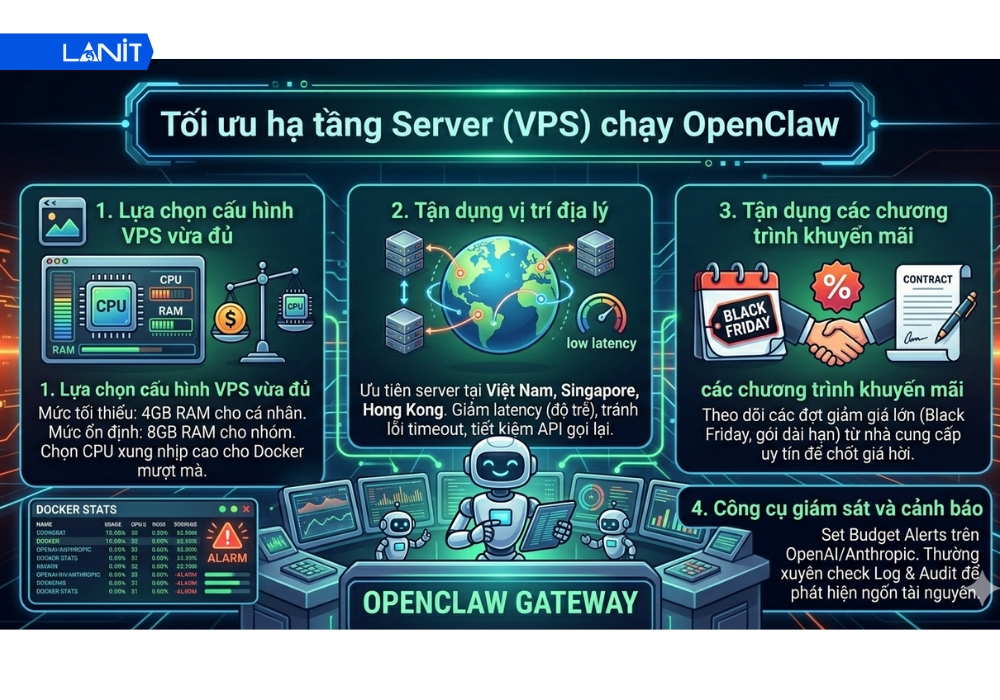
2. Tối ưu hạ tầng Server/VPS chạy OpenClaw
Nếu LLM là bộ não thì VPS chính là cơ thể của Agent. Một cơ thể quá yếu sẽ khiến AI hoạt động đình trệ, sinh lỗi và tiêu tốn thêm tiền để khắc phục; ngược lại, một cơ thể quá đồ sộ lại gây lãng phí tài nguyên không cần thiết. Tìm kiếm “điểm rơi phong độ” cho cấu hình VPS không chỉ giúp OpenClaw vận hành mượt mà hơn mà còn là cách bạn ổn định chi phí hạ tầng cố định hàng tháng.
- Cấu hình khuyến nghị: Tối thiểu 4GB RAM cho cá nhân và 8GB RAM cho nhóm nhỏ. Nên chọn VPS KVM để Docker vận hành mượt mà nhất.
- Vị trí địa lý: Ưu tiên server tại Việt Nam, Singapore hoặc Hong Kong để giảm độ trễ (Latency). Độ trễ thấp giúp giảm lỗi timeout – nguyên nhân khiến Agent phải gọi API lại nhiều lần.
*Mẹo nhỏ: Hãy canh các đợt giảm giá từ các nhà cung cấp uy tín như LANIT để chốt gói VPS dài hạn, giúp giảm chi phí hạ tầng cố định hàng tháng.
3. Quản lý logic và luồng vận hành của Agent
Công nghệ chỉ thực sự hiệu quả khi nó đi kèm với tính kỷ luật. Trong OpenClaw, tính kỷ luật đó nằm ở cách bạn thiết lập các giới hạn và quy trình xử lý dữ liệu thông minh. Bằng cách can thiệp vào cách Agent ghi nhớ và tương tác, chúng ta có thể loại bỏ tới 90% những dữ liệu rác – những “vật cản” vô hình đang âm thầm kéo dài lịch sử hội thoại và làm phồng hóa đơn của bạn.
- Thiết lập “Kill Switch”: Giới hạn số bước thực hiện tối đa (max_iterations: 12). Nếu sau 10-15 bước Agent vẫn không xong việc, hãy để nó dừng lại thay vì chạy mãi mãi.
- Sử dụng Local Embedding (QMD): Từ bản v2026.2.2, hãy dùng tính năng QMD. Thay vì gửi toàn bộ lịch sử, Agent chỉ tìm kiếm và gửi đi các đoạn thông tin liên quan nhất, giúp giảm 60-97% lượng token.
- Lịch trình (Scheduling) thông minh: Tăng khoảng cách kiểm tra “nhịp tim” (Heartbeat) từ 1 giờ lên 3 giờ và bật lightContext: true. Bạn sẽ ngạc nhiên khi thấy mình tiết kiệm được hàng chục USD chỉ nhờ bớt đi những lượt “hỏi thăm” vô ích của AI.
*Mẹo nâng cao: Đặt Temperature = 0.3-0.5 cho task cần độ chính xác, và dùng Early Stopping khi Agent đã có kết quả khả dụng. Sự kết hợp này tạo ra một “phễu” lọc dữ liệu: Temperature thấp giữ cho dòng suy nghĩ của Agent đi đúng đường ray, và Early Stopping là rào chắn ngăn không cho dòng suy nghĩ đó kéo dài quá mức cần thiết. Kết quả là hệ thống vận hành cực kỳ tiết kiệm, giảm thiểu độ trễ (latency) và giúp ngân sách API của bạn duy trì được lâu hơn đáng kể.
4. Sử dụng các mô hình mã nguồn mở (Open Source)
Nếu bạn có lượng tác vụ cực lớn và lặp lại, hãy nghĩ đến việc tự vận hành mô hình trên server riêng qua Ollama hoặc vLLM.
- Các mô hình như Llama 3.2 (3B), Qwen 2.5 Coder có thể chạy tốt trên VPS và xử lý các tác vụ định dạng văn bản với chi phí bằng 0.
- Khi nào nên chuyển sang Local LLM? Chỉ nên tự chạy khi bạn chi trên 25-30 USD/tháng cho API. Với VPS 8GB RAM (CPU Ryzen) đã có thể chạy ổn 2-3 Agent local. Nếu có GPU sẽ chạy được model mạnh hơn (14B-32B).
*Lưu ý về điểm hòa vốn: Chỉ nên tự chạy Local LLM nếu bạn thuê được VPS có GPU hoặc RAM lớn (>16GB). Với người dùng phổ thông, việc sử dụng Gemini Flash (với mức giá siêu rẻ) vẫn là lựa chọn ổn định và tiết kiệm thời gian hơn.
Công cụ giám sát và cảnh báo chi phí
Đừng đợi đến khi nhận email báo nợ từ nhà cung cấp mới bắt đầu lo lắng. Trong cuộc chơi AI Agent, sự chủ động chính là lợi nhuận. Để bảo vệ túi tiền, bạn cần thiết lập một hệ thống “phòng thủ” đa tầng từ Dashboard cho đến hệ thống Log nội bộ.
1. Thiết lập Budget Alert
Hầu hết các nhà cung cấp API lớn (OpenAI, Anthropic, Google Vertex AI) đều cung cấp công cụ quản lý hạn mức. Đừng bỏ qua chúng:
- Ngưỡng cảnh báo (Usage Limits): Thay vì chỉ đặt một mức, hãy đặt theo bậc thang. Ví dụ: Cảnh báo qua Email ở mức 50%, thông báo đẩy (Push) ở mức 75% và Tự động ngắt kết nối (Hard Limit) khi đạt 100% ngân sách tháng.
- Quản lý theo API Key: Nếu bạn chạy nhiều dự án khác nhau, hãy tạo các API Key riêng biệt cho từng Agent. Điều này giúp bạn định danh chính xác “kẻ tội đồ” nào đang lãng phí ngân sách mà không cần phải đoán mò.
2. Log & Audit
OpenClaw Gateway cung cấp một kho dữ liệu quý giá về cách Agent tương tác. Bạn nên thực hiện kiểm tra định kỳ thông qua các chỉ số:
- Phân tích Token per Request: Nếu một Agent thường xuyên có những yêu cầu vượt quá 10,000 token, đó là dấu hiệu của việc bối cảnh (context) đang bị phình to quá mức hoặc file dữ liệu đầu vào chưa được xử lý gọn.
- Giám sát Docker Stats: Sử dụng lệnh docker stats trực tiếp trên VPS để theo dõi mức chiếm dụng tài nguyên. Một Agent bị treo trong vòng lặp vô hạn thường sẽ đẩy CPU lên cao bất thường liên tục.
- Kiểm tra lịch sử hội thoại: Hãy đọc ngẫu nhiên (sampling) các đoạn log để phát hiện xem Agent có đang trả lời quá dài dòng hoặc lặp lại những câu trả lời vô nghĩa hay không.
Việc tối ưu chi phí khi sử dụng OpenClaw không chỉ giúp bạn tiết kiệm tiền mà còn giúp hệ thống AI vận hành thông minh và bền vững hơn. Bằng cách áp dụng linh hoạt các phương pháp từ việc lựa chọn mô hình ngôn ngữ phù hợp, tận dụng phần cứng có sẵn cho đến việc tinh chỉnh các tiến trình tự động hóa, bạn hoàn toàn có thể sở hữu một hệ thống AI mạnh mẽ mà vẫn đảm bảo tính kinh tế. Hãy bắt đầu từ những thay đổi nhỏ nhất ngay hôm nay để thấy được sự khác biệt trong dài hạn và khai phá tối đa tiềm năng mà OpenClaw mang lại cho công việc của bạn.