Việc phụ thuộc vào một model AI duy nhất chính là “tử huyệt” khiến hệ thống OpenClaw của bạn vừa tốn kém, vừa dễ bị gián đoạn. Giải pháp nằm ở kiến trúc đa mô hình: linh hoạt điều phối sức mạnh giữa OpenAI, Claude và các model Local để tối ưu hóa hiệu suất thực tế. Bạn sẽ sở hữu một hệ thống Agent chạy mượt mà 24/7, đạt tốc độ phản hồi tức thì trong khi vẫn tiết kiệm tới 80% chi phí vận hành.
⇒ Xem thêm: Mẹo tối ưu chi phí khi sử dụng OpenClaw tránh vượt ngân sách
Kết nối nhiều model AI cho OpenClaw mang đến những lợi ích gì?
Việc không phụ thuộc vào một model duy nhất không chỉ là vấn đề kỹ thuật, mà còn là chiến lược kinh doanh giúp tối ưu hóa lợi nhuận và trải nghiệm khách hàng:
- Tối ưu chi phí: Bạn có thể tiết kiệm từ 50-80% chi phí vận hành bằng chiến lược phân cấp mô hình (Model Tiering). Các tác vụ đơn giản như kiểm tra định kỳ (heartbeat) nên dùng model giá rẻ như Gemini Flash-Lite, dành ngân sách cho các tác vụ tư duy phức tạp với Claude Opus hay GPT-5.2.
- Tăng tốc độ xử lý: Các model nhỏ có ưu thế về Latency (độ trễ). Ví dụ, Gemini Flash có khả năng phản hồi lên đến 250 tokens/giây, giúp Agent tương tác với người dùng gần như tức thì.
- Dự phòng (Redundancy): Thiết lập chuỗi dự phòng (fallback chain) đảm bảo hệ thống luôn Uptime 99.9%. Nếu Anthropic bị giới hạn băng thông (rate limit), hệ thống sẽ tự động chuyển sang OpenAI hoặc Groq.
- Tính chuyên môn hóa: Mỗi model có một “biệt tài” riêng. Bạn có thể dùng DeepSeek-Coder cho lập trình, trong khi dùng Claude để xử lý các tài liệu đòi hỏi tính tuân thủ và văn phong tinh tế.

Các bước chuẩn bị trước khi kết nối
Trước khi bắt tay vào cấu hình, bạn cần chuẩn bị một nền tảng hạ tầng ổn định để đảm bảo API không bị nghẽn mạch. Việc chuẩn bị kỹ lưỡng về API Key và môi trường thực thi sẽ giúp bạn tránh được 90% lỗi kết nối phổ biến, đảm bảo Agent vận hành mượt mà ngay từ lần đầu tiên.
- Tài khoản nhà cung cấp: Đăng ký API Key từ OpenAI, Anthropic, Google Cloud (Vertex AI). Đảm bảo tài khoản đã kích hoạt Billing và kiểm tra hạn mức (Rate Limit) để tránh bị ngắt quãng khi đang vận hành.
- Môi trường thực thi: Cài đặt Node.js 22+. Nếu triển khai thực tế, hãy ưu tiên VPS (tối thiểu 2 vCPU/2GB RAM) để đảm bảo độ trễ (Latency) thấp nhất khi gọi API quốc tế.
- Công cụ hỗ trợ: Sử dụng VS Code để chỉnh sửa file cấu hình openclaw.json. Đặc biệt, hãy chuẩn bị sẵn môi trường dòng lệnh (CLI) để thực hiện debug hệ thống qua bộ công cụ tích hợp của OpenClaw.
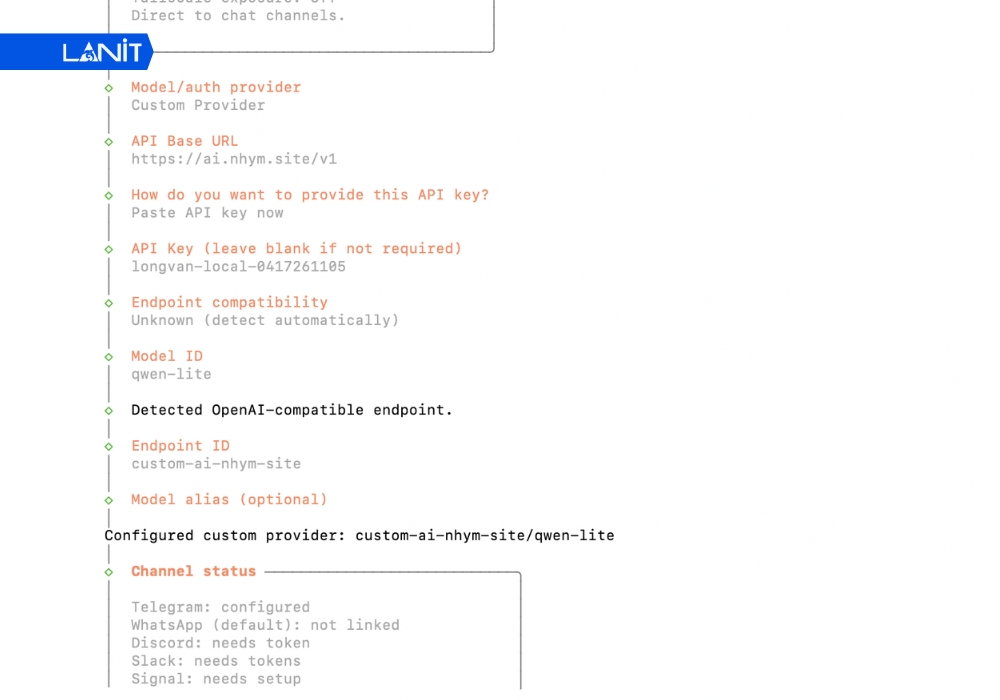
Hướng dẫn kết nối OpenClaw với các model AI phổ biến
Đây là quy trình chuyển hóa cấu hình thành sức mạnh thực thi thực tế. OpenClaw hỗ trợ cơ chế “Plug-and-Play”, cho phép bạn tích hợp linh hoạt từ các dịch vụ Cloud hàng đầu đến các model Local chạy tại chỗ. Dưới đây là cách thiết lập chuẩn xác để kết nối đa hệ sinh thái AI.
1. Kết nối với các model Cloud (OpenAI, Claude, Gemini)
OpenClaw sử dụng định dạng JSON5 linh hoạt trong file ~/.openclaw/openclaw.json.
Bước 1: Khai báo Provider.
Mở file cấu hình, tìm đến mục models.providers và thêm block thông tin:
- id: Tên định danh (ví dụ: my-claude).
- api: Giao thức kết nối (ví dụ: anthropic-messages).
- apiKey: Dán mã khóa API của bạn vào đây.
Bước 2: Thiết lập base URL.
Nếu sử dụng qua Proxy hoặc bên trung gian để tối ưu đường truyền, bạn cần thêm dòng baseUrl.
*Lưu ý: Luôn đảm bảo đường dẫn chính xác (thường kèm hậu tố /v1) để Agent gửi yêu cầu đúng địa chỉ.

⇒ Xem thêm: Hướng dẫn cài đặt OpenClaw kết hợp với ChatGPT từ A – Z
2. Kết nối với các model Local qua Ollama hoặc LM Studio
Sử dụng model chạy tại chỗ là lựa chọn tuyệt vời để tiết kiệm chi phí API và bảo mật dữ liệu tuyệt đối. Toàn bộ dữ liệu không rời khỏi máy chủ, không tốn phí token và hoạt động ổn định ngay cả khi không có internet quốc tế.
- Quy trình kết nối Ollama:
- Khởi động Ollama Server (mặc định tại http://localhost:11434).
- Trong OpenClaw, khai báo provider là ollama.
- Kéo các model như Llama 3 hoặc Mistral về máy và điền tên model vào cấu hình.
- Quy trình kết nối LM Studio:
- Bật chế độ Local Server trên LM Studio (thường dùng cổng 1234).
- OpenClaw sẽ hỗ trợ kết nối này như một nhà cung cấp gốc thông qua địa chỉ Localhost.
3. Tích hợp qua các Provider tốc độ cao (Groq, Œ)
Để Agent đạt tốc độ phản hồi “tức thì” nhờ phần cứng LPU chuyên dụng, hãy làm như sau:
Bước 1: Đăng ký tài khoản tại Groq hoặc Together AI và tạo API Key.
Bước 2: Cấu hình trong OpenClaw bằng giao thức openai-completions.
Bước 3: Thay đổi baseUrl thành endpoint của Groq (ví dụ: https://api.groq.com/openai/v1). Giờ đây, Agent của bạn sẽ xử lý các tác vụ Shell phức tạp chỉ trong tích tắc.
Cách chuyển đổi giữa các model trong quá trình sử dụng
OpenClaw cho phép bạn thay đổi “bộ não” của Agent linh hoạt thông qua 3 phương thức thực hiện sau:
- Sử dụng lệnh Prompt: Ngay trong giao diện chat, bạn gõ lệnh /model <tên-model>. . Ví dụ: /model anthropic/claude-3.5-sonnet. Hệ thống sẽ chuyển đổi model ngay lập tức cho câu trả lời tiếp theo.
- Thiết lập cấu hình mặc định (Default Model): Để Agent luôn khởi động với một model nhất định, hãy truy cập file cấu hình, tìm mục agents.defaults.model.primary và điền ID của model bạn muốn ưu tiên.
- Phân quyền theo Skill/Agent: Bạn có thể tạo nhiều Agent chuyên biệt.
- Agent Code: Cấu hình dùng gpt-4o hoặc deepseek-coder.
- Agent Summary: Cấu hình dùng gemini-1.5-flash để tối ưu token và tốc độ.
*Lưu ý quan trọng: Sau mỗi lần chỉnh sửa file cấu hình, bạn bắt buộc phải chạy lệnh sau:
openclaw doctor --fix
Lệnh này giúp hệ thống tự động rà soát lỗi cú pháp JSON và đảm bảo các thay đổi được áp dụng chính xác mà không gây treo hệ thống.
Việc làm chủ kỹ thuật kết nối đa mô hình không chỉ giúp bạn tối ưu hóa hiệu suất cho OpenClaw mà còn là chìa khóa để xây dựng một hệ sinh thái AI linh hoạt và bền vững. Thay vì phụ thuộc vào một nhà cung cấp duy nhất, giờ đây bạn đã có thể tự do luân chuyển giữa sức mạnh tính toán khổng lồ của các Cloud API và sự riêng tư, tiết kiệm của các mô hình chạy Local. Hãy nhớ rằng, một hệ thống tự động hóa thực sự mạnh mẽ không nằm ở việc sở hữu model đắt tiền nhất, mà nằm ở cách bạn phối hợp chúng để tạo ra quy trình Trigger-Process-Output chuẩn xác.