HBase là gì?
HBase là một cơ sở dữ liệu phân tán mã nguồn mở được xây dựng dựa trên Hadoop Distributed File System (HDFS), mô phỏng theo Bigtable của Google. HBase viết bằng Java, là một cơ sở dữ liệu hướng cột NoSQL, cung cấp khả năng lưu trữ và xử lý dữ liệu quy mô lớn, truy cập theo thời gian thực. Nó được xây dựng cho các hoạt động có độ trễ thấp, tính năng cụ thể hơn so với các mô hình quan hệ truyền thống.

Tính năng chính của Apache HBase
Khả năng mở rộng cao
Apache HBase có khả năng mở rộng theo chiều ngang, thêm nhiều máy chủ hơn vào cụm, giúp quản lý hiệu quả dữ liệu lớn, đảm bảm mỗi máy chủ xử lý một phần dữ liệu cân bằng để giảm tình trạng tắc nghẽn và tăng hiệu suất hoạt động. Mặt khác, việc phân phối đồng đồng trên các máy chủ để duy trì hiệu suất cũng ngăn không cho máy chủ đơn lẻ nào trở thành nút thắt cổ chai, đảm bảo tính khả dụng và độ tin cậy cao.
Hiệu suất
HBase cung cấp độ trễ thấp cho hoạt động đọc và ghi vào lượng lớn dữ liệu có cấu trúc, bán cấu trúc và không có cấu trúc. Hệ thống sử dụng lưu trữ trong bộ nhớ để tăng tốc độ truy cập dữ liệu. Dữ liệu trước khi vào đĩa sẽ được ghi vào bộ nhớ, giúp giảm thời gian cần thiết để truy xuất dữ liệu. HBase cũng sử dụng bộ lọc Bloom để giảm số lần đọc đĩa không cần thiết và nâng cao hiệu suất.
Ngoài ra, hệ thống HBase còn có thể xử lý số lượng lớn các yêu cầu đọc và ghi cùng lúc, giúp nó phù hợp với các ứng dụng yêu cầu xử lý dữ liệu nhanh. Kiến trúc hỗ trợ xử lý song song, cho phép nhiều hoạt động diễn ra đồng thời, đảm bảo xử lý hiệu quả các tập dữ liệu lớn.
Quản lý dữ liệu
HBase cung cấp thiết kế lược đồ linh hoạt, sắp xếp dữ liệu thành các bảng, hàng và họ cột. Mỗi bảng có thể có nhiều họ cột, mỗi họ chứa nhiều cột. Điều này cho phép thay đổi lược đồ động mà không bị ngừng hoạt động. Người dùng có thể thêm hoặc xóa các cột khi cần, giúp HBase thích ứng với nhiều mô hình dữ liệu khác nhau.
Hệ thống HBase hỗ trợ một số thuật toán nén như LZO, GZIP và Snappy. Dữ liệu nén cần ít không gian lưu trữ, giúp giảm chi phí và cải thiện hiệu suất đọc. Tính năng này của Apache HBase thích hợp để quản lý các tập dữ liệu lớn.
Apache HBase cũng đảm bảo độ bền dữ liệu với khả năng sao chép dữ liệu trên nhiều máy chủ. Điều này giúp chống lại việc mất dữ liệu trong trường hợp phần cứng bị lỗi đồng thời tăng cường hiệu suất đọc khi cho phép truy cập dữ liệu từ nhiều vị trí. Apache HBase sử dụng sao chép không đồng bộ để giảm tác động đến hiệu suất ghi.
Tích hợp đa dạng với nhiều công nghệ
- Hệ sinh thái Hadoop
HBase tích hợp liền mạch với hệ sinh thái Hadoop, đảm bảo độ bền dữ liệu và khả năng chịu lỗi. HBase có thể đóng vai trò vừa là đầu vào vừa là đầu ra cho các tác vụ Hadoop MapReduce. Giúp xử lý hiệu quả các tập dữ liệu lớn. Mặt khác, HBase cũng hỗ trợ Apache Hive, cho phép truy vấn giống SQL trên các bảng HBase.
- Apache Phoenix
Apache Phoenix cung cấp một lớp SQL trên Apache HBase, cho phép người dùng thực hiện các truy vấn SQL trên các bảng HBase. Giúp đơn giản việc truy cập và thao tác dữ liệu. Phoenix biên dịch các truy vấn SQL thành các phép quét và hoạt động HBase gốc, đảm bảo hiệu suất tối ưu và độ trễ thấp. Phoenix còn hỗ trợ lập chỉ mục thứ cấp, tham gia và giao dịch. Những tính năng này giúp nó trở thành một công cụ mạnh mẽ để truy vấn dữ liệu HBase.
- Apache Spark
Apache Spark là một công cụ xử lý dữ liệu trong bộ nhớ nhanh, cho phép Spark đọc và ghi vào các bảng HBase và phân tích dữ liệu HBase theo thời gian thực. Thư viện học máy của Spark (MLlib) cũng có thể tận dụng dữ liệu HBase để hỗ trợ các ứng dụng phân tích nâng cao và học máy. Sự kết hợp giữa HBase và Spark giúp nâng cao hiệu quả xử lý dữ liệu lớn.
Kiến trúc thành phần của Apache HBase
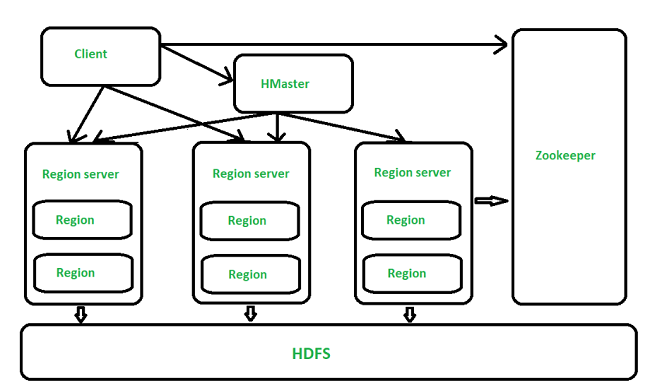
HBase bao gồm các thành phần chính sau:
- HMaster – là thành phần quản lý trong HBase, chịu trách nhiệm quản lý metadata của các bảng, theo dõi điều phối các Region Server, phân vùng lại dữ liệu và quản lý các hoạt động của Schema.
- RegionServer – là thành phần để lưu trữ dữ liệu và xử lý các yêu cầu từ Client. Mỗi Region Server chịu trách nhiệm quản lý một hoặc nhiều Region. Nó thực hiện truy vấn đọc/ghi từ client, lưu trữ dữ liệu trên HDFS, ghi dữ liệu, tự động chia Region khi dữ liệu trong một Region vượt quá kích thước cấu hình.
- Region – là đơn vị phân vùng dữ liệu nhỏ nhất trong HBase. Mỗi region đại diện cho một tập hợp con các hàng trong bảng. Khi một Region đạt ngưỡng kích thước, nó sẽ tự động chia thành nhiều Region con.
- HDFS – làm tầng lưu trữ cơ bản, cung cấp khả năng lưu trữ phân tán, bền vững và đáng tin.
- ZooKeeper – thành phần điều phối và quản lý trạng thái hệ thống. Nó có vai trò theo dõi trạng thái của các HMaster và RegionServer, lưu trữ thông tin cấu hình bảng và phân phối region và đảm bảo tính sẵn sàng, điều phối các client đến các RegionServer phù hợp.
Cách thức hoạt động của Apache HBase
Cách HBase ghi dữ liệu:
Hệ thống ghi dữ liệu của HBase đảm bảo tính bền vững và hiệu suất cao, được thực hiện theo các bước sau:
- Bước 1: Client gửi yêu cầu ghi dữ liệu đến RegionServer tương ứng với Region lưu trữ hàng mã dữ liệu cần ghi.
- Bước 2: Trước khi bắt đầu, HBase sẽ ghi bản sao dữ liệu vào WAL trên HDFS.
- Bước 3: Tiếp đến, dữ liệu sẽ được lưu tạm thời vào MemStore (RAM) của RegionServer. Giúp tối ưu hiệu suất.
- Bước 4: Khi MemStore đạt ngưỡng kích thước cấu hình, dữ liệu sẽ được ghi xuống HFile trên HDFS hay còn gọi là Flush. Sau đó, MemStore sẽ được giải phòng.
- Bước 5: Tiến hành hợp nhất dữ liệu. Gộp các Hfile nhỏ thành tệp lớn để giảm số lượng tệp cần quản lý, xóa dữ liệu bị đánh dấu xóa và hợp nhất các HFile lớn.
Cách HBase đọc dữ liệu:
Quá trình đọc dữ liệu của HBase được tối ưu để tìm kiếm và trả kết quả nhanh chóng, chính xác. Nó diễn ra theo các bước sau:
- Bước 1: Client gửi yêu cầu Đọc đến RegionServer tương ứng
- Bước 2: RegionServer sẽ tiến hành tìm kiếm dữ liệu. Đầu tiên sẽ tìm kiếm dữ liệu mới nhất chưa được Flush xuống HDFS, sau đó tìm dữ liệu đã được cache từ các HFile trước đó. Nếu không tìm thấy dữ liệu cần thiết, RegionServer truy vấn HDFS để tìm dữ liệu trong các HFile.
- Bước 3: RegionServer trả kết quả về client sau khi tổng hợp kết quả từ các nguồn.
Ưu nhược điểm của HBase
Ưu điểm
- Có Khả năng mở rộng cao bằng cách thêm các RegionServer vào cụm.
- Hỗ trợ lưu trữ quản lý số lượng lớn các hàng, cột mà không ảnh hưởng đến hiệu suất
- Được tối ưu hóa để truy cập theo thời gian thực, phù hợp ứng dụng yêu cầu đọc/ghi dữ liệu với độ trễ thấp
- Tích hợp chặt chẽ với hệ sinh thái Hadoop và hỗ trợ tích hợp các công cụ khác như Apache Hive, Apache Pig, Apache Spark để phân tích dữ liệu.
- Được tối ưu hóa cho khối lượng dữ liệu lớn như các ứng dụng Big Data, IoT, hệ thống gợi ý hoặc phân tích log.
Nhược điểm
- HBase không hoàn toàn tuân thủ ACID
- Để chạy HBase, cần ZooKeeper – một máy chủ để phối hợp phân tán như cấu hình, bảo trì và đặt tên.
- Không hỗ trợ tốt truy vấn phức tạp, cần tích hợp với các công cụ Apache Hive hoặc MapReduce để sử dụng
- Yêu cầu kinh nghiệm và năng lực để cấu hình và tối ưu hệ thống
- Phụ thuộc vào Hadoop, đòi hỏi tài nguyên và chi phí cao để triển khai một hệ sinh thái Hadoop hoàn chỉnh
- Không lý tưởng cho các ứng dụng với dữ liệu nhỏ hoặc yêu cầu độ trễ thấp.
Ứng dụng của Apache HBase
Apache HBase lý tưởng để sử dụng trong các trường hợp sau:
Phân tích thời gian thực: Được ứng dụng trong các tổ chức tài chính hoặc trong các công ty viễn thông
Kho dữ liệu: Phù hợp với các tổ chức lưu trữ dữ liệu thô lớn với Data Lakes hoặc các quy trình ETL (Trích xuất, Chuyển đổi, Tải).
Hoạt động của IoT: Dùng để quản lý dữ liệu cảm biến từ các thiết bị IoT hoặc các ứng dụng cần giám sát theo thời gian thực với độ trễ thấp
So sánh Apache HBase và MongoDB
Sau đây là những điểm khác biệt giữa Apache HBase và MongoDB chi tiết:
| Apache HBase | MongoDB | |
| Nguồn gốc | Lấy cảm hứng từ Google Bigtable và dựa trên Hadoop | Phát triển độc lập bởi MongoDB Inc |
| Kiến trúc | Phân tán dựa trên HDFS, có khả năng mở rộng cao | Hướng tài liệu, cấu trúc JSON/BSON |
| Ngôn ngữ truy vấn | Giao tiếp qua API Java, REST, Thrift. | Sử dụng ngôn ngữ truy vấn riêng của MongoDB MQL. |
| Cấu trúc dữ liệu | Dữ liệu lưu dưới dạng bảng với hàng và cột | Dữ liệu lưu dưới dạng tài liệu |
| Khả năng mở rộng | Mở rộng theo chiều ngang tốt bằng cách thêm máy chủ vào cụm | Khả năng mở rộng theo chiều ngang tốt thông qua phân mảnh |
| Hiệu suất | Hiệu suất nhất quán cho việc đọc/ghi dữ liệu | Thay đổi tùy theo độ phức tạp của truy vấn |
| Ứng dụng | Phù hợp với các ứng dụng yêu cầu phân tích thời gian thực và lưu trữ dữ liệu quy mô lớn | Phù hợp cho các ứng dụng cần thiết kế lược đồ linh hoạt, truy vấn phức tạp |
So sánh Apache HBase với RDBMS
Chúng ta cùng đi tìm hiểu những điểm khác biệt giữa Apache HBase và RDBMS thông qua bảng dưới đây nhé!
| Apache HBase | RDBMS | |
| Loại cơ sở dữ liệu | NoSQL | Cơ sở dữ liệu quan hệ |
| Lược đồ | Không yêu cầu lược đồ cố định | Yêu cầu lược đồ chặt chẽ và cấu trúc bảng rõ ràng |
| Cấu trúc dữ liệu | Dữ liệu được lưu dưới dạng bảng với hàng và cột không cố định | Dữ liệu lưu dưới dạng bảng với các hàng và cột có mối quan hệ với nhau. |
| Khả năng mở rộng | Mở rộng theo chiều ngang bằng cách thêm các RegionServer vào cụm | Mở rộng dọc |
| Hiệu suất | Tối ưu cho truy cập ngẫu nhiên và dữ liệu lớn | Phù hợp cho ứng dụng nhỏ đến trung bình với dữ liệu có cấu trúc |
| Quản lý giao dịch | Không cung cấp đầy đủ các giao dịch ACID | Tuân thủ ACID đây đủ. Đảm bảo toàn vẹn và độ tin cậy dữ liệu |
| Phục hồi lỗi | Tích hợp với HDFS và ZooKeeper để phục hồi dữ liệu | Dựa vào các công cụ như backup, replica hoặc cluster. |
| Ứng dụng | Dữ liệu lớn, phân tán, truy cập ngẫu nhiên với độ trễ thấp, lưu trữ log, dữ liệu thời gian thực | Dữ liệu có cấu trúc và quan hệ chặt chẽ, ứng dụng doanh nghiệp, ngân hàng, CRM, hệ thống yêu cầu giao dịch mạnh mẽ, phức tạp. |
Lời kết
Trên đây, LANIT đã chia sẻ chi tiết về Apache HBase – một cơ sở dữ liệu phân tán dùng để lưu trữ và quản lý dữ liệu lớn, hỗ trợ truy cập ngẫu nhiên theo thời gian thực với độ trễ thấp được phát triển dựa trên Hadoop. Nếu doanh nghiệp bạn hoạt động trong các lĩnh vực cần xử lý dữ liệu lớn theo thời gian thực và đòi hỏi độ trễ thấp thì đây là giải pháp lý tưởng cho bạn.
Ngoài ra, nếu bạn cần từ vấn thêm về dịch vụ lưu trữ tại LANIT như dịch vụ VPS, dịch vụ máy chủ giá rẻ liên hệ ngay để được hỗ trợ sớm nhất nhé!