Apache Airflow là gì?
Apache Airflow là nền tảng mã nguồn mở để phát triển, lên lịch và giám sát luồng công việc. Airflow là giải pháp mạnh mẽ, hữu ích cho việc thiết kế và sắp xếp các đường ống dữ liệu phức tạp và khởi tạo luồng công việc dưới dạng Directed Acyclic Graphs (DAG) của các tác vụ.

Airflow có giao diện người dùng phong phú, được phân phối, có thể mở rộng và hoạt động linh hoạt, giúp nó phù hợp để xử lý việc sắp xếp logic, dữ liệu phức tạp.
DAG trong Airflow là gì?
DAG trong Apache Airflow là cấu trúc cốt lỗi dùng để tổ chức và lập lịch các workflow, mỗi DAG sẽ biểu diễn một tập hợp các tác vụ chạy theo thứ tự cụ thể và mối quan hệ phụ thuộc giữa chúng. Trong đó:
- Directed: Các task được kết nối bằng các cạnh có hướng, cho biết thứ tự công việc.
- Acyclic: DAG không chứa bất kỳ chu trình nào, đảm bảo một task không thể phụ thuộc trực tiếp hoặc gián tiếp vào chính nó.
- Graph: DAG được thể hiện ở dạng đồ thị, trong đó node là task, edge là mối quan hệ phụ thuộc giữa các task.
Apache Airflow được dùng để làm gì?
Apache Airflow được sử dụng trong các trường hợp sau đây:
- Lập lịch công việc tự động: Airflow cho phép lập lịch công việc để chạy theo một trình tự như hàng ngày, hàng giờ hoặc tùy chỉnh.
- Sao lưu và các tác vụ DevOps khác: Như gửi tác vụ Spark và lưu trữ dữ liệu kết quả trên Hadoop Cluster.
- Quản lý quy trình công việc phức tạp: Airflow cung cấp khả năng biểu diễn các công việc phức tạp với các task phụ thuộc lẫn nhau.
- Điều phối công việc ETL hàng loạt: Airflow thường dùng để xây dựng và tự động hóa ETL Pipeline như Extract (trích xuất dữ liệu hàng loạt từ nhiều nguồn), Transform (xử lý và chuẩn hóa dữ liệu) và Load ( lưu trữ dữ liệu đã xử lý vào kho dữ liệu.
- Theo dõi và giám sát công việc: Với giao diện mạnh mẽ, Airflow giúp người dùng theo dõi và giám sát trạng thái thực thi các tác vụ, khởi động lại khi các tác vụ bị lỗi, truy vập log, tạo báo cáo,…
- Xử lý dữ liệu lớn: Airflow có thể tích hợp với các công cụ xử lý dữ liệu lớn trong Apache như Spark, Hive, và Presto để chạy các quy trình xử lý dữ liệu lớn và phức tạp.
- Đào tạo mô hình học máy: Airflow còn được dùng để tự động hóa các pipeline học máy, đào tạo mô hình học máy.
Các thành phần chính trong Apache Airflow
Sau đây là các thành phần chính trong Apache Airflow
DAG (Directed Acyclic Graph)
Trong Airflow, các đường ống được biểu diễn dưới dạng DAG, được định nghĩa trong Python. DAG không có chu trình đảm bảo workflow không có vòng lặp vô hạn.
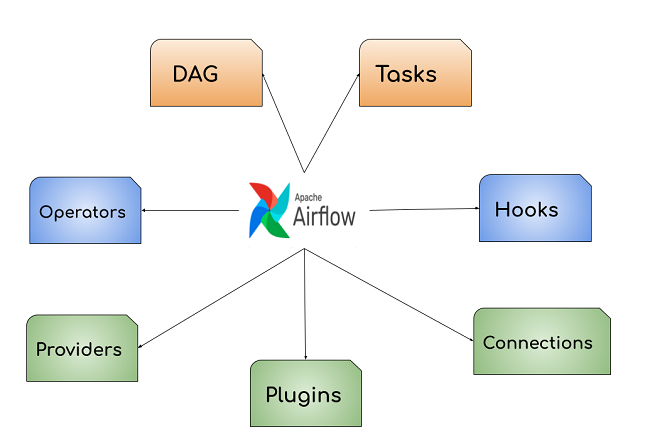
Task (Tác vụ)
Mỗi một nút trong DAG sẽ biểu diễn một Task, nó thể hiện một loạt các tác vụ cần thực hiện, tạo thành một đường ống. Các task biểu diễn được xác định bằng các Operators. Trong đó, Operators là công cụ dùng để tạo task.
Operators (toán tử)
Các operators là các khối xây dựng cơ bản của Airflow, được dùng để xác định công việc đã thực hiện. Operators có thể là một task riêng (nút của DAG), xác định cách thực hiện task.
DAG đảm bảo các Operators được lên lịch và thực hiện công việc theo thứ tự cụ thể và các Operators sẽ xác định công việc sẽ thực hiện ở mỗi bước trong quy trình công việc.
Có 3 loại Operator chính đó là các toán tử chạy một hàm như PythonOperator hoặc Bash Operator; toán tử truyền cho phép truyền dữ liệu từ nguồn đến đích như S3ToRedshiftOperator. Cuối cùng là toán tử FileSensor được sử dụng để chời một tệp trong thư mục trược khi tiếp tục thực hiện đường ống. Các Operator có thể trao đổi thông tin bằng Xcom.
Hooks
Hooks trong Airflow được dùng để giao tiếp với các hệ thống hoặc dịch vụ của bên thứ 3, cho phép kết nói giữa API và cơ sở dữ liệu bên ngoài như Hive, S3, GCS, MySQL, PostgreSQL,… Các thông tin nhạy cảm như thông tin đăng nhập được lưu trữ bên ngoài Hooks, được lưu trữ trong cơ sở dữ liệu đã được mã hóa liên kết với phiên bản Airflow hiện tại.
Plugins
Các Plugins Airflow có thể được mô tả như sự kết hợp giữa Hooks và Operators. Chúng được dùng để thử hiện các tác cụ liên quan đến các ứng dụng bên ngoài. Mỗi Plugin do cộng đồng người dùng tạo ra phục vụ các mục đích cụ thể.
Connections
Connections cho phép Airflow lưu trữ thông tin, kết nối với các hệ thống bên ngoài như thông tin xác thực API, mã thông báo. Chúng được quản lý trực tiếp từ giao diện người dùng. Dữ liệu được mã hóa và lưu trữ ở dạng siêu dữ liệu trong cơ sở dữ liệu PostgresSQL hoặc MySQL.
Ưu điểm – hạn chế của Apache Airflow
Ưu điểm
- Là nền tảng mã nguồn mở miễn phí với cộng đồng người dùng đông đảo
- Dễ sử dụng nếu bạn có kiến thức về Python
- Giao diện người dùng đồ họa để theo dõi và quản lý quy trình công việc, kiểm tra trạng thái của các Task đang thực hiện và đã hoàn thành. Đồng thời dễ dàng khắc phục sự cố với tính năng retry và re-run task.
- Tích hợp mạnh mẽ với các nền tảng dịch vụ đám mây, hệ thống hay các công cụ xử lý dữ liệu, hỗ trợ xây dựng Plugin và operator tùy chỉnh.
- Được viết bằng Python – là ngôn ngữ phổ biến và dễ sử dụng. Giúp bạn tạo quy trình làm việc linh hoạt bằng Python.
- Có thể mở rộng dễ dàng để xử lý các khối lượng công việc lớn, hỗ trợ chạy song song nhiều task trên nhiều máy hoặc container.
Hạn chế
- Độ phức tạp ban đầu khi thiết lập và cấu hình
- Không được tối ưu hóa cho các quy trình công việc theo thời gian thực hay cần phản hồi ngay lập tức. Có độ trễ nhất định
- Mở rộng quy mô khó khăn
- Việc truyền dữ liệu giữa các task hạn chế
- Đòi hỏi tài nguyên đáng kể, nhất là để xử lý nhiều DAG phức tạp.
Lời kết
Trên đây, LANIT đã chia sẻ chi tiết về Apache AirFlow – một nền tảng để phát triển, lên lịch và giám sát luồng công việc. Đây được đánh giá là nền tảng linh hoạt để tối ưu hóa quy trình công việc trong các dự án cần xử lý dữ liệu lớn, DevOps, và khoa học dữ liệu.
Bạn và đội ngũ của mình đang phát triển dự án dữ liệu lớn và cần thuê VPS, Cloud Server hoặc thuê Server vật lý để hỗ trợ thử nghiệm, lưu trữ dữ liệu, liên hệ ngay LANIT để được tư vấn và báo giá tốt nhất nhé!