


Apache hive là gì?
Apache Hive là một hệ thống kho dữ liệu mã nguồn mở dùng để đọc, ghi và quản lý các tệp dữ liệu lớn, phân tích dữ liệu có cấu trúc. Hive được xây dựng dựa trên nền tảng Apache Hadoop, giao diện giống SQL, sử dụng HiveQL để truy vấn dữ liệu. Nó có 3 chức năng chính là tóm tắt, truy vấn và phân tích dữ liệu.

Hive hỗ trợ ngôn ngữ thao tác dữ liệu DML, ngôn ngữ định nghĩa dữ liệu DDL và hàm UDF. Với việc mở rộng tài liệu và các bản cập nhật liên tục, Apache Hive đang tiếp tục được cải tiến việc xử lý dữ liệu theo cách dễ truy cập hơn.
Kiến trúc của Hive
Sau đây là các thành phần kiến trúc chính của Hive và mô tả của chúng:
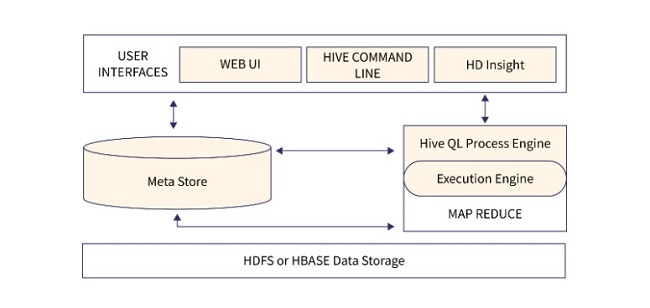
Giao diện người dùng (User Interface):
Hive là phần mềm cơ sở hạ tầng kho dữ liệu có thể tạo sự tương tác giữa người dùng và HDFS. Hỗ trợ các giao diện người dùng như Hive Web UI, Hive command line và Hive HD Insight (Windows Server). Để giao tiếp với Hive, người dùng gửi hướng dẫn và truy vấn đến các giao diện khác nhau.
MetaStore:
Hive chọn các máy chủ cơ sở dữ liệu tương ứng để lưu trữ lược đồ hoặc Metadata của bảng, cơ sở dữ liệu, các cột, kiểu dữ liệu và ảnh xạ HDFS. MetaStore cung cấp dịch vụ quản lý và truy xuất dữ liệu và lưu trữ trong cơ sở dữ liệu như MySQL hoặc PostgreSQL.
Công cụ xử lý HiveQL (HiveQL Process Engine):
Hive sử dụng ngôn ngữ HiveQL để truy vấn thông tin và quản lý dữ liệu. Người dùng có thể tạo truy vấn bằng cú pháp SQL trong HiveQL và chuyển đổi chúng thành các tác vụ MapReduce hoặc Apache Tez để thực thi.
Execution Engine:
Phần kết hợp của công cụ xử lý HiveQL và MapReduce là Hive Execution Engine. Nó xử lý truy vấn và tạo kết quả giống như kết quả MapReduce. Việc thực thi các tác vụ trên các tài nguyên điện toán phân tán được lên lịch và phối hợp bởi công cụ thực thi như Apache Spark, MapReduce và Apache Tez.
HDFS hoặc HBASE:
Hive sử dụng HDFS hoặc HBASE làm nền tảng cho lưu trữ dữ liệu, các tập dữ liệu lớn có thể được lưu trữ theo cách có khả năng chịu lỗi, có thể mở rộng bằng HDFS. Đây là nơi Hive đọc và ghi dữ liệu.
Cách thức hoạt của Apache Hive
Sau đây là cách thức hoạt động của Apache Hive:
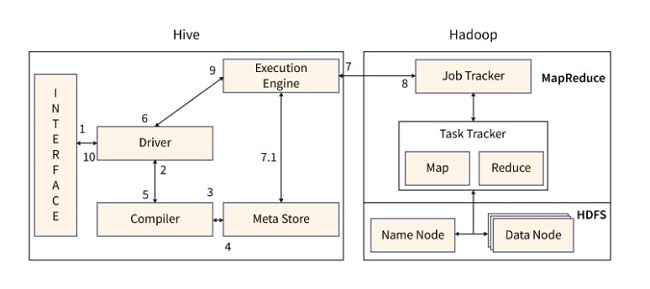
- Thực hiện truy vấn: Thông qua giao diện, người dùng sẽ gửi lệnh hoặc truy vấn đến trình điều khiển Hive để thực thi.
- Nhận kế hoạch: Trình điều khiển sẽ sử dụng trình biên dịch truy vấn để phân tích cú pháp truy vấn nhằm kiểm tra cú pháp hoặc yêu cầu của truy vấn.
- Nhận siêu dữ liệu: Trình biên dịch sẽ gửi yêu cầu siêu dữ liệu đến Metastore.
- Gửi siêu dữ liệu: Metastore gửi siêu dữ liệu dưới dạng phản hồi tới trình biên dịch
- Gửi Kế hoạch: Kế hoạch được gửi lại cho trình điều khiển sau khi trình biên dịch đã kiểm tra yêu cầu. Quá trình xử lý và biên dịch truy vấn đã được hoàn tất.
- Thực hiện kế hoạch: Trình điều khiển gửi kế hoạch thực hiện đến công cụ thực hiện
- Thực hiện công việc: Một tác vụ MapReduce được dùng trong nội bộ để thực thi tác vụ. Công cụ thực thi sẽ gửi tác vụ đến JobTracker trong nút Name, và phân phổ cho TaskTracker trong nút Data. Tại đây, truy vấn sẽ thực thi công việc MapReduce.
- Hoạt động siêu dữ liệu: Công cụ thực thi có thể thực hiện các hoạt động siêu dữ liệu với Metastore như tạo và xóa bảng.
- Lấy kết quả: Công cụ thực thi nhận kết quả từ các nút dữ liệu để gửi kết quả tới trình điều khiển Hive.
Ưu điểm – hạn chế của Apache Hive
Ưu điểm
- Hive quen thuộc, nhanh chóng và có khả năng mở rộng, nâng cấp tốt. Người dùng dễ dàng tăng hoặc giảm máy chủ ảo theo nhu cầu.
- Hive lưu trữ lược đồ trong cơ sở dữ liệu và xử lý dữ liệu trong HDFS, đồng thời có thể phân tích các tập dữ liệu lớn trong HDFS.
- Dễ sử dụng, dễ học nhờ sử dụng ngôn ngữ giống SQL
- Cho phép nhiều loại lưu trữ khác nhau như Parquet, văn bản thuần túy, RCFile và HBase,…
- Hive có thể hoạt động trên dữ liệu nén được lưu trữ trong hệ sinh thái Hadoop bằng thuật toán.
- Hỗ trợ hàm do người dùng định nghĩa UDF để thao thác ngày tháng, chuỗi,…hỗ trợ mở rộng để xử lý các trường hợp không được hỗ trợ bởi các hàm tích hợp.
- Các khối lượng công việc có thể được sao chép để phục hồi sau thảm họa
- Hive sử dụng lập chỉ mục để tăng tốc truy vấn, bộ dữ liệu có thể hỗ trợ tới 100.000 truy vấn/giờ.
Hạn chế
- Hive không có khả năng xử lý dữ liệu theo thời gian thực, nên có độ trễ truy vấn cao
- Không được thiết kế để xử lý dữ liệu phát trực tuyến, giao dịch trực tuyến hoặc thu thập dữ liệu theo thời gian thực.
- Xử lý phức tạp và cập nhật các tập dữ liệu trong khuôn khổ Hadoop với MapReduce
- Hỗ trợ hạn chế cho các thao tác Cập Nhật và Xóa.
HiveQL là gì?
HiveSQL (HQL hay HiveQL) là ngôn ngữ truy vấn được sử dụng trong Apache Hive. Nó cho phép tạo và quản lý bảng, phân vùng một cách thuận tiện, cung cấp cách thức dễ dàng để truy vấn, phân tích và thao tác dữ liệu trong môi trường phân tán.
Đặc điểm chính của HiveQL:
- Cú pháp tương tự với SQL, người dùng dễ làm quen và thao tác khi quen với SQL
- Hỗ trợ truy vấn và xử lý dữ liệu lớn bằng cách chuyển đổi các câu lệnh HQL thành các tác vụ MapReduce, Tez hoặc Spark.
- Hỗ trợ nhiều định dạng dữ liệu khác nhau
- Tối ưu hóa để sử dụng trong hệ sinh thái Hadoop, tương thích với các công cụ lưu trữ và xử lý dữ liệu như HDFS, HBase.
- Hỗ trợ các tính năng như phân mảnh dữ liệu, chia nhóm để cải thiện hiệu suất xử lý.
So sánh Apache Hive với Apache Pig
Apache Hive và Apache Pig là hai thành phần quan trọng trong Hadoop với mục đích hoạt động khác nhau. Sau đây là một số điểm khác biệt chính giữa hai nền tảng này nhé!

| Apache Hive | Apache Pig | |
| Đối tượng sử dụng | Thường được các nhà phân tích dữ liệu sử dụng | Thường được các lập trình viên, nhà nguyên cứu sử dụng |
| Ngôn ngữ sử dụng | Sử dụng ngôn ngữ HiveQL, tương tự SQL | Sử dụng ngôn ngữ lập trình thủ tục Pig Latin, tuân theo ngôn ngữ luồng dữ liệu |
| Xử lý dữ liệu | Xử lý dữ liệu có cấu trúc | Xử lý dữ liệu bán cấu trúc, dữ liệu không có cấu trúc |
| Hoạt động | Hoạt động phía máy chủ của cụm HDFS | Hoạt động ở phía máy khách của cụm HDFS |
| Hiệu suất | Chậm hơn Pig do xử lý nhiều truy vấn, thiếu tối ưu hóa luồng dữ liệu | Nhanh hơn so với Hive |
| Tích hợp | Tích hợp tốt với các công cụ BI và báo cáo nhờ giao diện SQL-Like | Mạnh mẽ trong chuyển đổi và làm sạch dữ liệu |
| Cộng đồng | Cộng đồng lớn mạnh, ứng dụng nhiều trong các doanh nghiệp với kho dữ liệu Hadoop | Cộng đồng hạn chế hơn Hive, phù hợp với các dự án tùy chỉnh và phức tạp. |
Lời kết
Trên đây, LANIT đã chia sẻ chi tiết về Apache Hive – một framework dữ liệu lớn hỗ trợ phân tích và xử lý dữ liệu lớn trong Hadoop. Đây sẽ là lựa chọn tuyệt vời trong việc xử lý và phân tích dữ liệu lớn dựa trên sức mạnh của hệ sinh thái Hadoop.
Ngoài ra, nếu bạn cần mua VPS giá rẻ hoặc thuê Server vật lý để lưu trữ dữ liệu lớn hoặc thử nghiệm dự án mới, liên hệ ngay LANIT để được tư vấn chi tiết nhé!












