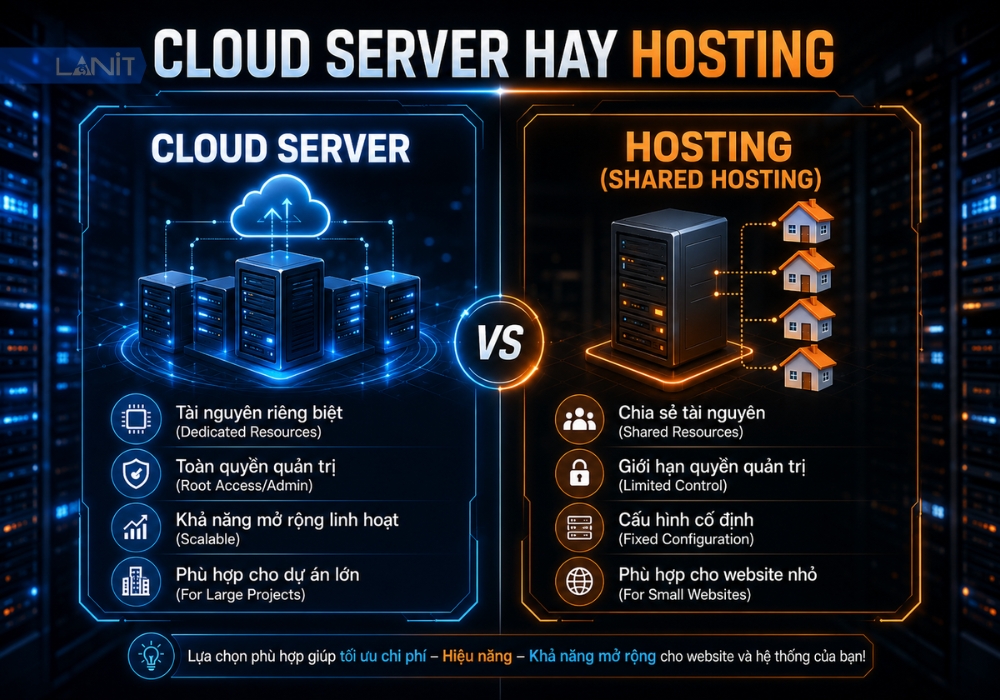
Web Scraping là gì?
Web scraping hay còn gọi là web harvesting hoặc web data extraction – là quá trình tự động lấy dữ liệu từ các trang web. Các công cụ web scraping thường truy cập vào trang web thông qua giao thức HTTP hoặc bằng cách mô phỏng hành vi của trình duyệt web để thu thập thông tin mà họ cần. Điều này có thể được thực hiện thủ công, nhưng thường thì web scraping đề cập đến việc tự động thu thập dữ liệu sử dụng BOT hoặc Web Crawler.
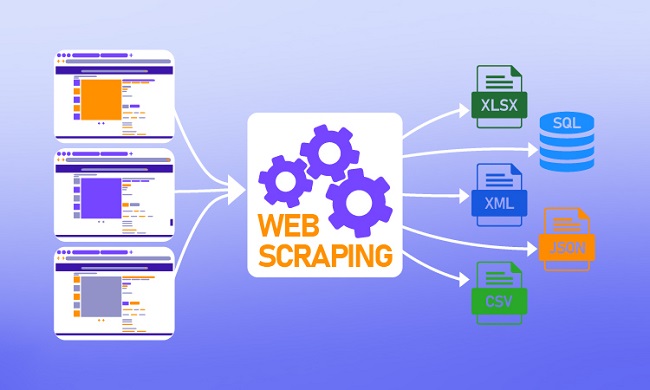
Cách thức hoạt động của Web Scraping
Quy trình hoạt động của Web scraping tương đối đơn giản. Tuy nhiên, khi cần thu thập dữ liệu ở quy mô lớn, bạn có thể đối mặt với nhiều thách thức. Các bước thu thập dữ liệu gồm:
- Xác định trang web mục tiêu.
- Thu thập các URL của trang web bạn muốn lấy dữ liệu.
- Gửi yêu cầu đến các URL để nhận HTML của trang web.
- Sử dụng bộ phân tích để tìm kiếm dữ liệu trong HTML.
- Lưu dữ liệu trích xuất vào các định dạng như JSON, CSV hoặc các định dạng khác có cấu trúc.
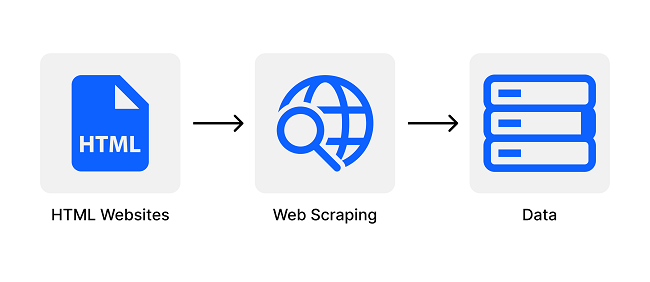
Web Scraping cấu tạo cũng như hoạt động theo hai phần là Web Crawler và Web Scraper
- Web Crawler (trình thu thông tin): là chương trình thông minh được dùng để tìm kiếm nội dung trên Internet bằng cách theo dõi các liên kết và khám phá website. Trong nhiều dự án, bạn cần thu thập dữ liệu web hoặc tìm tới một website cụ thể để khám phá các URL cho công cụ trích xuất dữ liệu web.
- Web Scraper (trình xuất dữ liệu): là công cụ giúp trích xuất dữ liệu từ một website một cách chính xác và nhanh chóng. Mỗi web scraper có thiết kế và độ phức tạp khác nhau. Tuy nhiên, bộ phận quan trọng của mọi web scraper là bộ định vị dữ liệu, giúp tìm kiếm dữ liệu trong file HTML. CSS, Xpath, regex thường được sử dụng làm bộ định vị dữ liệu.
Ứng dụng của Web Scraping
Web Scraping có ứng dụng đa dạng trong nhiều lĩnh vực khác nhau, góp phần vào sự phát triển của kinh tế và công nghiệp. Dưới đây là một số ứng dụng phổ biến của Web Scraping:
- Phân tích thị trường: Thu thập và phân tích thông tin về giá cả, sản phẩm để giúp doanh nghiệp đưa ra quyết định dựa trên dữ liệu chính xác nhất.
- Sản xuất nội dung: Tạo ra nội dung mới và chất lượng bằng cách thu thập thông tin từ các nguồn khác nhau trên Internet.
- Giám sát thị trường: Theo dõi hoạt động của đối thủ cạnh tranh và các công ty trong cùng ngành để hiểu rõ hơn về chiến lược kinh doanh và cải thiện sức mạnh cạnh tranh.
- Phát hiện vi phạm bản quyền: Giám sát việc sao chép nội dung hoặc tìm kiếm các trang web vi phạm bản quyền.
- Nghiên cứu và phân tích dữ liệu: Thu thập dữ liệu từ nhiều nguồn để phục vụ cho mục đích nghiên cứu và phân tích dữ liệu.
Thực hiện Web Scraping như thế nào?
Có nhiều cách thực hiện Web Scraping, từ sử dụng các thư viện mã nguồn mở như Scrapy, BeautifulSoup đến việc sử dụng các dịch vụ Web Scraping trả phí như ScrapingHub, Import.io. Bạn cũng có thể sử dụng các trình duyệt web có tích hợp sẵn công cụ Web Scraping như Octoparse, Parsehub.
Khi nào Web Scraping bị coi là độc hại?
Khi dữ liệu bị trích xuất mà không được chủ website cho phép thì Web Scraping là độc hại. Hai trường hợp phổ biến là:
Content Scraping
Content scraping là việc trộm cắp nội dung quy mô lớn từ một trang web nhất định. Đối tượng thường là các danh mục sản phẩm trực tuyến hoặc các trang web dựa trên nội dung số để thúc đẩy doanh nghiệp. Đối với họ, việc bị tấn công bởi content scraping có thể gây tổn thất lớn.
Ví dụ, các doanh nghiệp địa phương thường dành nhiều thời gian và tiền bạc để xây dựng cơ sở dữ liệu nội dung của họ. Scraping có thể dẫn đến việc thông tin của họ bị phát tán, sử dụng cho spam hoặc bán cho đối thủ cạnh tranh. Những việc này có thể gây ra hậu quả nghiêm trọng cho hoạt động kinh doanh hàng ngày của họ.
Price Scraping
Trong price scraping, hacker thường sử dụng botnet để tự động quét các cơ sở dữ liệu giá cả. Họ muốn lấy thông tin về giá cả, đánh bại đối thủ và tăng doanh số bán hàng.

Các cuộc tấn công thường xảy ra ở các ngành có sản phẩm dễ so sánh giá. Các nạn nhân thường là các công ty du lịch, người bán vé và cửa hàng điện tử.
Ví dụ, các cửa hàng điện thoại thông minh thường sử dụng price scraping. Họ luôn cập nhật giá để cạnh tranh. Để làm điều này, họ sử dụng bot để kiểm tra giá cả của đối thủ và điều chỉnh giá của họ.
Bảo mật Web Scraping như thế nào?
Sự tăng số lượng BOT Scraper gây ra những thách thức cho các biện pháp bảo mật thông thường. Để đối phó, Imperva sử dụng phân tích chi tiết về lưu lượng truy cập để đảm bảo tính hợp pháp của mọi nguồn lưu lượng truy cập tới website, bao gồm cả con người và bot. Quá trình bao gồm:
- Kiểm tra header HTTP để phát hiện bot và xác định tính độc hại.
- Sử dụng dữ liệu IP để xác minh nguồn gốc và lịch sử tấn công.
- Phân tích hành vi truy cập để phát hiện các dấu hiệu bất thường.
- Áp dụng các thách thức liên tục như yêu cầu hỗ trợ cookie và thực thi JavaScript để loại bỏ bot. Một CAPTCHA có thể được sử dụng như một phương án cuối cùng để phát hiện và ngăn chặn bot.
Kết luận
Bài viết trên đây của LANIT đã giải thích Web Scraping là gì? cũng như những điều căn bản mà người mới cần biết. LANIT hy vọng những thông tin trên đã giúp ích cho bạn và hãy theo dõi để cập nhật thêm các thông tin về công nghệ nhé!