Batch processing là gì?
Batch processing (hay xử lý hàng loạt hoặc xử lý theo lô) là một phương pháp xử lý lượng lớn dữ liệu được thu thập và xử lý cùng lúc thay vì xử lý riêng lẻ hoặc theo thời gian thực. Phương pháp này cho phép xử lý một cách hiệu quả và tự động các tác vụ lặp lại, hoặc cần xử lý lượng lớn dữ liệu, hữu ích để xử lý các tác vụ đòi hỏi sức mạnh tính toán lớn, tốn thời gian.
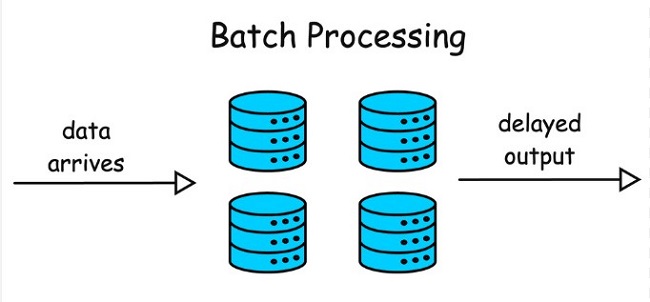
Cách Batch processing hoạt động như thế nào?
Batch processing hoạt động bằng cách chia nhỏ lượng lớn dữ liệu hoặc chia theo lô và xử lý các lô này theo các bước như sau:
- Thu thập dữ liệu: Đầu tiên, cần thu thập dữ liệu từ nhiều nguồn khác nhau như hệ thống, cơ sở dữ liệu hoặc tệp bên ngoài. Dữ liệu sẽ được thu thập và sắp xếp thành các đợt để xử lý.
- Chuẩn bị dữ liệu: Dữ liệu sẽ được chuẩn bị để làm sạch, xác thực và định dạng để đảm bảo tính nhất quán, chính xác. Các lỗi trong dữ liệu sẽ được sửa chữa trước khi bắt đầu tiến hành xử lý dữ liệu.
- Xử lý theo lô: Dữ liệu sẽ được xử lý theo lô, mỗi lô chứa một tập hợp con của toàn bộ dữ liệu. Tùy vào yêu cầu của mỗi ứng dụng sẽ có các tác vụ được áp dụng cho dữ liệu, nó có thể bao gồm tính toán, sắp xếp, lọc, chuyển đổi,…
- Xử lý lỗi: Trong quá trình dữ liệu được xử lý hàng loạt, có thể xảy ra lỗi, lỗi này có thể đến từ việc dữ liệu không nhất quán, lỗi phần cứng,….Hệ thống xử lý lỗi sẽ gồm các cơ chế phát hiện và xử lý lỗi một cách phù hợp, nó bao gồm ghi lại lỗi, cảnh bảo cho quản trị viên và thử lại quá trình xử lý cho hàng loạt bị ảnh hưởng.
- Kết quả: Kết quả sẽ được tạo ra sau khi bạn tiến hành xử lý dữ liệu theo lô, kết quả có thể ở nhiều dạng khác nhau như báo cáo, tóm tắt hoặc cơ sở dữ liệu được cập nhật. Dữ liệu đã xử lý có thể được lưu trữ để phân tích thêm hoặc để cập nhật các hệ thống khác.
- Xử lý sau cùng: Sau khi tất cả các lô được xử lý, sẽ có các tác vụ hậu xử lý như tạo báo cáo cuối cùng, thực hiện các phân tích bổ sung hoặc lưu trữ dữ liệu đã xử lý. Sau đó, các tệp hoặc tài nguyên tạm thời sẽ được dọn dẹp để giải phóng tài nguyên hệ thống.
- Lên lịch: Các tác vụ xử lý hàng loạt thường được lên lịch chạy vào thời điểm cụ thể như thời gian hệ thống ít hoạt động để giảm tác động đến ứng dụng cũng như người dùng. Việc lên lịch đảm bảo các dữ liệu được xử lý thường xuyên và kịp thời.
Lợi ích khi sử dụng phương pháp Batch processing
Xử lý dữ liệu khối lượng lớn và lặp lại
Batch processing được thiết kế để xử lý khối lượng lớn dữ liệu và thực hiện các tác vụ lặp đi lặp lại như sao lưu dữ liệu, lọc, sắp xếp, xử lý bảng lương, lập hóa đơn,…Việc tập hợp dữ liệu theo lô để xử lý cùng lúc giúp xử lý công việc một cách nhanh chóng mà không làm chậm hệ thống.
Hiệu quả cao và giảm chi phí
Bằng cách xử lý dữ liệu theo từng lô, các tổ chức có thể sử dụng tài nguyên máy tính khi chúng khả dụng mà không cần sự can thiệp của con người. Giúp giảm nhu cầu xử lý thủ công, nâng cao năng suất lao động. Mặt khác, việc kết hợp nhiều tác vụ thành một lô để xử lý làm giảm chi phí liên quan đến các tác vụ xử lý riêng lẻ, tăng hiệu quả cho bộ xử lý, bộ nhớ và các tài nguyên điện toán khác.
Cải thiện Chất lượng dữ liệu
Batch processing đảm bảo xử lý dữ liệu nhất quán và chính xác bằng cách áp dụng các quy tắc và chuyển đổi đã được xác định trước với mỗi lô dữ liệu. Điều này giúp duy trì tính toàn vẹn và đảm bảo dữ liệu được xử lý nhất quán. Mặt khác, việc tự động hóa các tác vụ sẽ giảm tương tác của người dùng, giảm khả năng xảy ra lỗi, tăng độ chính xác và tin cậy để tạo ra dữ liệu chất lượng hơn.
Tích hợp và trao đổi dữ liệu
Batch processing có vai trò quan trọng trong việc tích hợp dữ liệu từ nhiều nguồn, cho phép trích xuất, chuyển đổi và tải dữ liệu, cho phép tích hợp và trao đổi dữ liệu giữa các hệ thống khác nhau. Điều này giúp tổ chức hợp nhất dữ liệu từ nhiều nguồn khác nhau thành một định dạng thống nhất để phân tích hoặc báo cáo.
Khả năng mở rộng
Việc xử lý dữ liệu theo từng đợt giúp các tổ chức dễ dàng điều chỉnh kích thước lô, tăng hoặc giảm quy mô dựa trên khối lượng công việc. Điều này, đảm bảo xử lý dữ liệu hiệu quả theo nhu cầu và đảm bảo có thể xử lý lượng lớn dữ liệu tăng lên khi cần.
Hoạt động ngoài giờ
Hệ thống Batch processing có thể được thiết lập để hoạt động vào những khung thời gian mà nhân viên đã nghỉ ngơi với chế độ nền. Điều này giúp hệ thống của bạn có thể hoạt động 24/7 phục vụ khách hàng hoặc chạy chương trình bất kể lúc nào. Bạn có thể thiết lập chế độ xử lý hàng loạt qua đêm để loại bỏ các rủi ro về kết quả xử lý hàng loạt làm gián đoạn hoạt động trong phiên làm việc.
Quy trình làm việc hiệu quả
Việc xử lý hàng loạt cho phép các công ty xử lý công việc khi máy tính hoặc các nguồn lực có sẵn. Họ có thể ưu tiên xử lý các tác vụ nhạy cảm về thời gian và lên lịch xử lý hàng loạt cho các công việc không khẩn cấp. Điều này cũng có thể thực hiện ngoại tuyến để giảm áp lực lên hệ thống hoặc bộ xử lý trong ngày làm việc.
Thách thức của Batch processing
Độ trễ: Batch processing thường tạo ra độ trễ trong việc xử lý dữ liệu, khiến nó không phù hợp sử dụng trong các trường hợp yêu cầu xử lý dữ liệu theo thời gian thực.
Lo ngại về Khả năng mở rộng: Khi khối lượng dữ liệu tăng lên, các hệ thống xử lý hàng loạt sẽ có hạn chế trong việc mở rộng. Điều này có thể khiến cho thời gian xử lý lâu hơn hoặc gây quá tải hệ thống từ đó làm tăng chi phí.
Độ phức tạp: hệ thống xử lý hàng loạt phải xử lý các phụ thuộc phức tạp giữa các tác vụ, điều này gây khó khăn cho việc quản lý và có thể yêu cầu một hệ thống lập lịch công việc phức tạp hơn. Ngoài ra, hệ thống cũng gây ra lo ngại về độ phức tạp trong xử lý lỗi và sử dụng tài nguyên trong quá trình xử lý để đảm bảo hiệu suất hệ thống.
Vấn đề bảo trì và giám sát: Batch processing đòi hỏi bảo trì thường xuyên và giám sát liên tục để phát hiện các sự cố, tối ưu hiệu suất và đảm bảo các tác vụ xử lý được thực hiện thành công.
Bảo mật dữ liệu: Xử lý dữ liệu nhạy cảm trong hệ thống sẽ làm tăng mối lo ngại về bảo mật. Việc duy trì dữ liệu được mã hóa, kiểm soát truy cập và tuân thủ các quy định bảo mật trong hệ thống sẽ tăng độ phức tạp cho các tác vụ xử lý hàng loạt.
Các công cụ hỗ trợ Batch processing
Các công cụ hỗ trợ Batch Processing hàng đầu hiện nay:
Hadoop: Là một Framework mã nguồn mở mạnh mẽ dùng để lưu trữ và xử lý dữ liệu lớn trên một cụm máy tính. Nó bao gồm Hadoop Distributed File System (HDFS) có nhiệm vụ lưu trữ dữ liệu và Hadoop MapReduce dùng để xử lụy dữ liệu. Công cụ này cho phép xử lý dữ liệu hàng hoạt bằng cách phân chia công việc xử lý trên nhiều máy tính trong cụm.
Spark: là hệ thống xử lý dữ liệu phân tán mã nguồn mở, giúp tối ưu tốc độ. Với tính dễ sử dụng và linh hoạt, công cụ này giúp xử lý dữ liệu hàng loạt và dữ liệu theo luồng, hỗ trợ một loạt các tác vụ từ phân tích đến học máy. Spark nhanh hơn so với Hadoop MapReduce trong việc thực hiện các tác vụ xử lý trên cùng một tập dữ liệu.
Hive: Là dự án mã nguồn mở, cung cấp giao diện SQL – like để truy vấn dữ liệu lưu trữ trong các hệ thống phân tán. Công cụ giúp đơn giản hóa việc phân tích dữ liệu hàng loạt bằng cách cung cấp ngôn ngữ HiveQL, thuận tiện cho những người đã làm quen với SQL.
MapReduce: Là mô hình lập trình cho việc xử lý và tạo dữ liệu hàng loạt, đây là thành phần cốt lõi của Hadoop. Nó tách quá trình xử lý thành 2 pha là pha Map và pha Reduce. pha Map dữ liệu đầu vào được chia thành các tập hợp nhỏ, được xử lý đồng thời và kết quả sẽ được tổng hợp và xử lý trong pha Reduce để có kết quả cuối cùng.
Các công cụ này đều hỗ trợ xử lý dữ liệu hàng loạt nhưng mỗi công cụ sẽ có những đặc điểm và lợi ích riêng. Tùy thuộc vào nhu cầu của từng dự án và tập dữ liệu để bạn lựa chọn công cụ phù hợp, tối ưu nhất. Cụ thể:
- Hadoop: dành cho các tác vụ yêu cầu xử lý dữ liệu hàng loạt lớn, phức tạp trên cụm máy tính phân tán
- Spark: Tốc độ nhanh hơn Hadoop, có thể xử lý cả dữ liệu hàng loạt lẫn dữ liệu luồng. Phù hợp với các tác vụ phân tích dữ liệu nâng cao.
- Hive: Phù hợp cho những ai quen với SQL và muốn áp dụng nó để phân tích dữ liệu hàng loạt trên Hadoop. Nó cũng hữu ích khi cần chuyển dữ liệu lớn từ Hadoop vào cơ sở dữ liệu SQL.
- MapReduce: Sử dụng khi bạn muốn tạo ứng dụng phân tán từ đầu.
So sánh Batch processing và Stream Processing
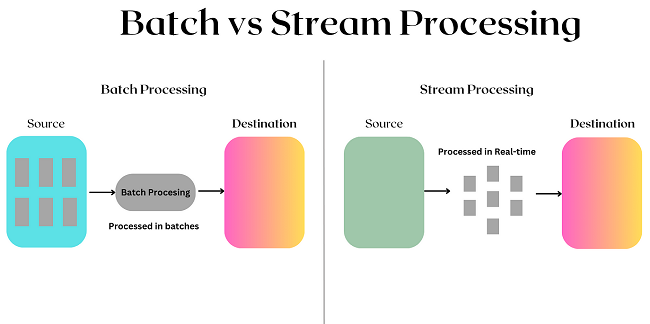
| Batch processing | Stream Processing |
| Dữ liệu được thu thập trong một khoảng thời gian nhất định trước và được xử lý theo lô hoặc theo nhóm | Dữ liệu được thu thập và xử lý theo luồng liên tục theo thời gian thực |
| Dữ liệu được xử lý ngoại tuyến hoặc được lên lịch theo khoảng thời gian nhất định | Dữ liệu được xử lý theo từng bản ghi hoặc sự kiện ngay khi nhận. |
| Phù hợp sử dụng khi dữ liệu có thể được thu thập và xử lý hàng loạt, không yêu cầu gần thời gian thực | Xử lý dữ liệu có độ trễ thấp, gần như thời gian thực, phù hợp sử dụng khi cần thông tin chi tiết kịp thời hoặc hành động ngay lập tức |
| Sử dụng cho các tác vụ ETL, phân tích hàng loạt, báo cáo | Sử dụng phân tích theo thời gian thực, phát hiện gian lận, giám sát thiết bị IoT, ra quyết định theo thời gian thực |
| Hiệu quả về chi phí, tối ưu tài nguyên và khả năng xử lý lượng lớn dữ liệu | Xử lý luồng dữ liệu tốc độ cao, phản hồi hanh chóng với các thay đổi hoặc sự kiện trong luồng dữ liệu |
Cụ thể các điểm khác nhau cơ bản giữa Batch processing và Stream Processing như sau:
- Độ nhạy thời gian: Batch processing tập trung xử lý dữ liệu được tích lũy trong một khoảng thời gian còn Stream Processing làm việc với nguồn dữ liệu theo thời gian thực.
- Độ trễ: Batch processing có độ trễ cao hơn Stream Processing vì phải chờ dữ liệu được thu thập trước khi xử lý, trong khi đó Stream Processing xử lý dữ liệu ngay khi nhận được.
- Khối lượng dữ liệu: Batch processing xử lý khối lượng dữ liệu lớn từ nhiều nguồn còn Stream Processing xử lý các luồng dữ liệu tốc độ cao.
- Độ phức tạp: Batch processing cho phép chuyển đổi và tính toán phức tạp hơn vì nó hoạt động trên một loạt dữ liệu, trong khi đó Stream Processing tập trung xử lý từng bản ghi hoặc sự kiện theo thời gian thực.
Tuy nhiên, các tổ chức có thể tận dụng cả hai phương pháp xử lý dữ liệu này trong một số trường hợp để tận dụng thế mạnh của mỗi cách xử lý dữ liệu, nâng cao hiệu quả xử lý dữ liệu. Tùy vào nhu cầu của doanh nghiệp và trường hợp nhất định để lựa chọn phương pháp phù hợp và tối ưu nhất.
Lời kết
Trên đây, LANIT đã chia sẻ chi tiết về Batch processing – một phương pháp xử lý dữ liệu hoặc tác vụ theo nhóm, theo lô hàng loạt, giúp các tổ chức tiết kiệm thời gian cũng như chi phí. Mặc dù vậy, đôi khi phương pháp này cần kết hợp với xử lý theo thời gian thực để đảm bảo độ trễ dữ liệu được cải thiện, giúp doanh nghiệp đưa ra được các quyết định, chiến lược phát triển phù hợp.
Nếu bạn còn thắc mắc nào hoặc cần tư vấn khi thuê VPS để lưu trữ dữ liệu, thử nghiệm dự án liên hệ ngay LANIT để được hỗ trợ sớm nhất nhé!








![[Kinh Nghiệm] Tư Vấn Chọn Hosting Cho Wordpress Ổn Định - Giá Rẻ](https://lanit.com.vn/wp-content/uploads/2023/11/front-view-man-website-hosting-concept.jpg)