Kafka là gì?
Apache Kafka hay Kafka là một nền tảng mã nguồn mở được phát triển bởi Apache Software Foundation và viết bằng Java và Scala. Kafka giúp xử lý dữ liệu phát trực tuyến theo thời gian thực, kết hợp giao tiếp, lưu trữ và xử lý luồng dữ liệu. Nó cho phép luồng dữ liệu không đồng bộ giữa các quy trình, ứng dụng và máy chủ Server như các hệ thống môi giới tin nhắn khác.

Nền tảng Kafka cung cấp thông lượng cao, độ trễ thấp và khả năng mở rộng linh hoạt đáp ứng các yêu cầu về dữ liệu lớn, phục vụ nhu cầu xử lý dữ liệu lớn trong thời gian thực.
Apache Kafka được dùng để làm gì?
Kafka thường được sử dụng để nhắn tin, theo dõi hoạt động của website, thu thập và giám sát số liệu, ghi nhật ký, phân tích theo thời gian thực,… Nó phù hợp sử dụng với các ứng dụng xử lý tin nhắn quy mô lớn và mạnh mẽ, có khả năng chịu lỗi hơn so với các ứng dụng hàng đợi tin nhắn truyền thống.
Thành phần chính và cách thức hoạt động của Kafka
Sau đây là các thành phần chính và cách thức hoạt động của Kafka:
Kafka Broker và Kafka Clusters
Kafka Broker là một máy chủ được tạo ra bởi nhiều broker hợp tác với nhau để cho phép cân bằng tải, dự phòng và chuyển đổi dự phòng. Mỗi phiên bản broker có thể xử lý khối lượng đọc – ghi lên đến hàng chục ngàn mỗi giây mà không ảnh hưởng hiệu suất. Mỗi Broker có một ID duy nhất và quản lý các bộ phận của một hay nhiều nhật ký chủ đề. Nó đóng vai trò cầu nối giữa Message Pulisher với Message Consumer để chúng có thể trao đổi tin nhắn với nhau.
Kafka chạy dưới dạng một Kafka cluster gồm một hoặc nhiều Kafka Server có thể mở rộng trên nhiều trung tâm dữ liệu hoặc Cloud. Chịu trách nhiệm quản lý bộ lưu trữ, xử lý yêu cầu cũng như sao chép dữ liệu, hoạt động như một cluster controller có trách nhiệm chỉ định phân vùng cho brokers và theo dõi lỗi của brokers.
Kafka ZooKeeper
ZooKeeper là dịch vụ điều phối phân tán mã nguồn mở nhằm duy trì thông tin cấu hình, đặt tên, đồng bộ hóa phân tán và cung cấp dịch vụ nhóm, được dùng để quản lý, lưu trữ và điều phối các brokers.
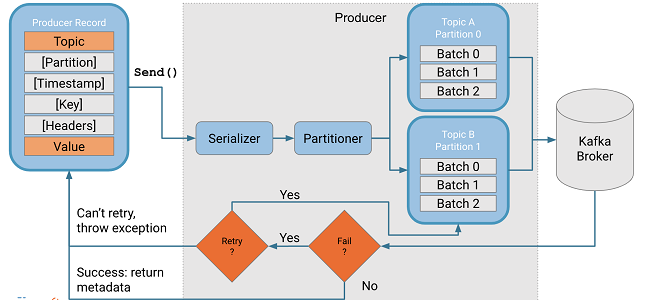
Kafka Producers
Kafka Producer là một ứng dụng Client, nó sẽ publish đều event trên tất cả partition của một topic, hoặc sẽ gửi trực tiếp event tới các partition cụ thể. Thành phần này kết nối với Kafka Brokers qua giao thức TCP.
Kafka Consumers
Kafka Consumers là một ứng dụng Client, subscribe một hoặc nhiều Kafka topics và đọc các bản ghi theo trình tự mà chúng được tạo ra. Ứng dụng này đọc dữ liệu theo thời gian thực nhanh chóng, cho phép các ứng dụng phản ứng với các sự kiện khi nó xảy ra. Kafka Consumers hoạt động như một nhóm consumer làm việc cùng nhau để xử lý dữ liệu từ các partitions, cung cấp khả năng mở rộng theo chiều ngang và cho phép nhiều phiên bản của ứng dụng xử lý dữ liệu đồng thời.
Kafka Topics
Dữ liệu truyền bên trong Kafka theo dạng Topics, khi cần truyền dữ liệu cho những ứng dụng riêng thì nó sẽ tạo ra các topic khác nhau tương ứng.
Kafka Partitions
Các topic được chia thành các partitions và mỗi partitions sẽ được lưu trữ trên một broker duy nhất độc lập với nhau và có thể mở rộng theo nhu cầu để cải thiện hiệu suất. Mỗi event trong một partition được gán một offset duy nhất, để xác định vị trí của event trong một partition.
Mỗi partition có thể có một hoặc nhiều replica (bản sao) trên các brokers khác nhau để ngăn ngừa mất dữ liệu khi broker lỗi. Mỗi partition sẽ có một broker làm leader có quyền sở hữu partition đó và các brokers khác sẽ lưu trữ các replicas của phân vùng đó được gọi là followers.
Khi leader broker có lỗi, một trong những followers có dữ liệu cập nhật sẽ làm leader mới. Quá trình này được gọi là leader failover để đảm bảo tính khả dụng của dữ liệu.
Kafka Events
Một Kafka event sẽ ghi lại các sự kiện trong doanh nghiệp được gọi là record hoặc message. Việc đọc và ghi dữ liệu trong Kafka được thực hiện thông qua event và mỗi Event sẽ chứa một key, value và metadata (nếu có).
Tính năng chính của Kafka
Apache Kafka cung cấp 3 tính năng chính sau:
Phân phối message
Kafka là lựa chọn tốt để xử lý message quy mô lớn với khả năng thông lượng cao, độ trễ thấp, phân đoạn tích hợp và khả năng sao chép cũng như chịu lỗi hơn so với các ứng dụng tin nhắn khác.
Event Streaming
Event Streaming chính là tính năng chủ yếu giúp thu thập dữ liệu dưới dạng các luồng sự kiện theo thời gian thực từ các nguồn sự kiện cơ sở dữ liệu, cảm biến hay các thiết bị di động và lưu trữ chúng lâu dài để có thể truy xuất, phân tích, xử lý trong thời gian thực và định tuyến các luồng sự kiện đến đích khác nhau.
Lưu trữ dữ liệu
Kafka sẽ lưu trữ tin nhắn ngay cả khi chúng đã được gửi đi để phòng tránh mất dữ liệu. Dữ liệu được lưu trữ có thể được truy xuất bất cứ lúc nào. Ngoài ra, nó có thể lưu trữ lượng lớn thông tin dữ liệu để tạo thành Data Lake. Đặc biệt, nó còn có thể thu thập và xử lý dữ liệu theo thời gian thực.
Ưu điểm – hạn chế của Kafka
Ưu điểm của Apache Kafka
- Mã nguồn mở miễn phí: Kafka là mã nguồn mở nên có thể dễ dàng sửa đổi, tùy chỉnh và mở rộng chức năng theo nhu cầu, tiết kiệm chi phí.
- Mở rộng dễ dàng: Cho phép mở rộng dễ dàng và liền mạch bằng cách thêm các broker vào cluster. Giúp tăng khả năng xử lý dữ liệu mà không cần thay đổi cấu trúc toàn bộ hệ thống.
- Xử lý theo thời gian thực: Cho phép truyền và xử lý dữ liệu theo thời gian thực, đáp ứng nhanh chóng các sự kiện mới xảy ra.
- Nhất quán và độ tin cậy cao: Điều này được thể hiện qua quá trình sao lưu và sao chép thông điệp giữa các broker, đảm bảo dữ liệu không bị mất đi và sẵn sàng cho các ứng dụng.
- Dữ liệu đa dạng: Kafka hỗ trợ xử lý dữ liệu đa dạng như logs, trạng thái ứng dụng, sự kiện liên quan khác,…
- Tích hợp linh hoạt: Có khả năng tích hợp linh hoạt với các công nghệ, ứng dụng khác và hỗ trợ nhiều giao thức truyền tải khác nhau.
- Lưu trữ dữ liệu lâu dài: Kafka cho phép lưu trữ dữ liệu lâu dài, bạn có thể lưu trữ, truy xuất dữ liệu để phân tích và kiểm tra.
- Cộng đồng mạnh mẽ: Kafka có cộng đồng lớn, mạnh mẽ, hỗ trợ nhanh chóng.
Hạn chế của Kafka
- Phụ thuộc vào Zookeepers: Các phiên bản cũ của kafka, nó phụ thuộc nhiều vào ZooKeeper làm tăng độ phức tạp và tiềm ẩn lỗi.
- Việc cài đặt, cấu hình và quản lý phức tạp: Yêu cầu người có chuyên môn để thực hiện và bảo trì, khó khăn với người mới.
- Yêu cầu tài nguyên phần cứng đáng kể: Kafka yêu cầu tài nguyên phần cứng đáng kể như bộ nhớ, dung lượng lưu trữ, dung lượng mạng và khả năng xử lý.
- Không tích hợp công cụ giám sát hoàn chỉnh: Có khá nhiều công cụ khác nhau và mỗi công cụ lại hỗ trợ một công việc quản lý khác nhau cho từng mục đích riêng.
- Hiệu suất hạn chế: Điều này xảy ra khi khối lượng, kích thước tin nhắn tăng lên, đòi hỏi consumer và producer phải decompress những tin nhắn đó. Điều này ảnh hưởng đến bộ nhớ và hiệu suất chung của hệ thống.
Ứng dụng của Apache Kafka
Sau đây là các ứng dụng nổi bật của Kafka:
- Sử dụng để xây dựng các hệ thống xử lý dữ liệu theo thời gian thực như hệ thống giám sát, theo dõi trạng thái ứng dụng, ghi nhật ký.
- Sử dụng để quản lý sự kiện và giao dịch tại các ngân hàng và tổ chức tài chính
- Sử dụng để phân tích dữ liệu lớn và xây dựng các data pipeline cho việc thu thập, xử lý và chuyển tiếp dữ liệu
- Ứng dụng trong lĩnh vực IoT để thu thập, xử lý lượng lớn dữ liệu từ các thiết bị kết nối mạng
- Ứng dụng trong các hệ thống ghi nhật ký phân tán giúp ghi lại các sự kiện, lỗi,…
- Sử dụng để kết nối và truyền thông dữ liệu giữa các ứng dụng, dịch vụ trong môi trường phân tán
- Sử dụng trong phân tích thời tiết và dữ liệu địa lý theo thời gian thực và lưu dữ liệu lâu dài
- Sử dụng trong các ứng dụng truyền thông thời gian thực để truyền dữ liệu hiệu quả.
Lời kết
Trêm đây, LANIT đã chia sẻ chi tiết các thông tin về Apache Kafka – một nền tảng mã nguồn mở dùng để xử lý luồng dữ liệu lớn trong thời gian thực và có thể dùng để truyền, lưu trữ và xử lý dữ liệu. Với thế mạnh về tính linh hoạt xử lý dữ liệu trong thời gian thực, đây là dịch vụ được ứng dụng rộng rãi hiện nay.
Nếu bạn cần thuê VPS, hoặc thuê Server giá rẻ để chạy các ứng dụng thời gian thực hoặc lưu trữ dữ liệu liên hệ ngay LANIT nhé!