Apache Flink là gì?
Apache Flink là một công cụ mã nguồn mở phân tán chuyên xử lý dữ liệu theo trạng thái, có thể xử lý cả dữ liệu không giới hạn (luồng) và dữ liệu có giới hạn (lô). Các ứng dụng sử dụng Flink được thiết kế để chạy liên tục, với thời gian gián đoạn tối thiểu và xử lý dữ liệu ngay khi dữ liệu được nhập vào hệ thống. Flink được tối ưu để xử lý với độ trễ thấp, thực hiện tính toán trong bộ nhớ, giúp tăng cường độ sẵn sàng. Đồng thời giảm thiểu rủi ro của các điểm lỗi đơn lẻ và hỗ trợ khả năng mở rộng theo chiều ngang.
Một số tính năng nổi bật của Apache Flink bao gồm quản lý trạng thái, bảo đảm tính nhất quán của dữ liệu với mô hình nhất quán. Công cụ xử lý sự kiện theo thời gian với khả năng xử lý dữ liệu không theo thứ tự và dữ liệu bị trễ. Flink được phát triển với ưu tiên cho xử lý luồng, đồng thời cung cấp một giao diện lập trình duy nhất cho cả xử lý luồng và xử lý theo lô.

Cấu trúc và thành phần chính của Apache Flink là gì?
Flink là một công cụ xử lý dữ liệu phân tán dựa trên một engine dòng dữ liệu, nhưng không có lớp lưu trữ riêng. Thay vào đó, nó sử dụng các hệ thống lưu trữ bên ngoài như HDFS (Hadoop Distributed File System), S3, HBase, Kafka, Apache Flume, Cassandra và bất kỳ cơ sở dữ liệu quan hệ (RDBMS). Điều này cho phép Flink xử lý dữ liệu từ bất kỳ nguồn nào và quy mô nào theo cách phân tán. Tại lõi của Flink là một engine xử lý phân tán hỗ trợ nhiều loại tác vụ, bao gồm xử lý theo lô, xử lý luồng, xử lý đồ thị và học máy.
Lớp tiếp theo trong kiến trúc của Flink là quản lý triển khai. Flink có thể được triển khai ở chế độ cục bộ (để kiểm tra và phát triển) hoặc theo cách phân tán cho môi trường sản xuất. Lớp quản lý triển khai bao gồm các thành phần như Flink-client, Flink-web UI, Flink-runtime, Flink-distributed shell và Flink-container. Các thành phần này hoạt động cùng nhau để quản lý việc triển khai và thực thi các ứng dụng Flink trên một cụm phân tán. Để chạy như một cụm đa nút, Flink được tích hợp chặt chẽ với các công cụ quản lý tài nguyên như YARN (Yet Another Resource Negotiator), Mesos, Docker, Kubernetes, hoặc ở chế độ độc lập.
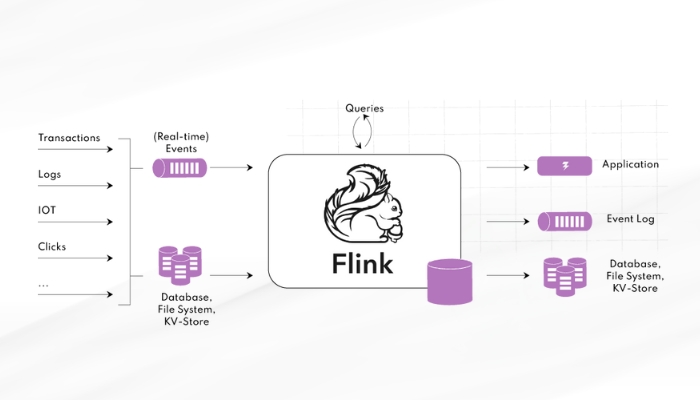
Flink Kernel là phần cốt lõi của hệ thống Apache Flink. Lớp runtime cung cấp khả năng xử lý phân tán, độ bền lỗi, tính đáng tin cậy và khả năng xử lý lặp lại một cách tự nhiên.
Engine thực thi (execution engine) quản lý các tác vụ Flink, là các đơn vị tính toán phân tán được phân phối trên nhiều nút trong cụm. Điều này giúp Flink có thể vận hành hiệu quả trên các cụm lớn.
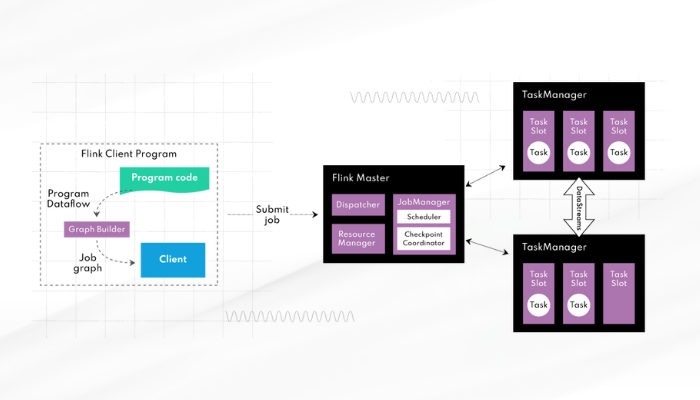
Flink sử dụng kiến trúc master/slave với JobManager và TaskManagers. JobManager chịu trách nhiệm lên lịch và quản lý các công việc đã được gửi tới Flink, đồng thời điều phối kế hoạch thực thi bằng cách phân bổ tài nguyên cho các tác vụ. Các TaskManagers có nhiệm vụ thực thi các hàm người dùng đã định nghĩa trên các tài nguyên đã được phân bổ, phân tán trên nhiều nút trong cụm.
Lợi thế của kiến trúc này là có thể mở rộng hiệu quả để xử lý các tập dữ liệu lớn trong thời gian gần như thực tế. Nó cũng cung cấp khả năng chịu lỗi và cho phép khôi phục công việc với tổn thất dữ liệu tối thiểu – điều này rất quan trọng đối với các ứng dụng yêu cầu độ tin cậy cao.
Vì sao nên sử dụng Apache Flink?
Apache Flink là công cụ xử lý dữ liệu mạnh mẽ, hỗ trợ cả xử lý dữ liệu theo lô và luồng. Các tính năng nổi bật bao gồm quản lý trạng thái nâng cao, xử lý sự kiện theo thời gian, và đảm bảo tính nhất quán “exactly-once”. Flink có thể xử lý dữ liệu lớn ở quy mô phân tán, đảm bảo hiệu suất cao và ít độ trễ. Nó hỗ trợ nhiều hệ thống kết nối như Kafka, HBase, Elasticsearch và các cơ sở dữ liệu JDBC.
Flink cung cấp các API linh hoạt (Streaming SQL, Table API, DataStream API) để xử lý các trường hợp sử dụng đơn giản đến phức tạp. Đồng thời hỗ trợ các ngôn ngữ như Java, Scala, Python, và Kotlin.

Ưu và nhược điểm của Apache Flink là gì?
Dù nhiều ưu điểm nhưng công cụ Apache Flink vẫn còn tồn tại một số nhược điểm, có thể xem dưới bảng sau:
| Ưu điểm | Nhược điểm |
| Hỗ trợ xử lý dữ liệu thời gian thực, độ trễ thấp | Triển khai và cấu hình phức tạp đối với người mới |
| Khả năng mở rộng linh hoạt | Cần phần cứng và tài nguyên cao |
| Tính nhất quán cao, đảm bảo chính xác | Tài liệu và cộng đồng hỗ trợ còn hạn chế |
| Tích hợp tốt với nhiều hệ thống như Hbase, Kafka, Elasticsearch,… | Khó duy trì trên quy mô lớn |
| Kết hợp xử lý theo lô luồng, giảm độ phức tạp | Yêu cầu kiến thức phức tạp nên khá khó đối với người học mới |
>>> Xem thêm: Những điều cần biết về Apache Server
Những trường hợp sử dụng Apache Flink
Apache Flink hỗ trợ cả dòng dữ liệu có giới hạn (bounded) và không giới hạn (unbounded), phù hợp cho nhiều ứng dụng, bao gồm:
- Ứng dụng điều khiển theo sự kiện: Flink xử lý các sự kiện từ nhiều luồng, cập nhật trạng thái và kích hoạt các hành động. Ví dụ: phát hiện gian lận, cảnh báo theo quy tắc, giám sát quy trình kinh doanh.
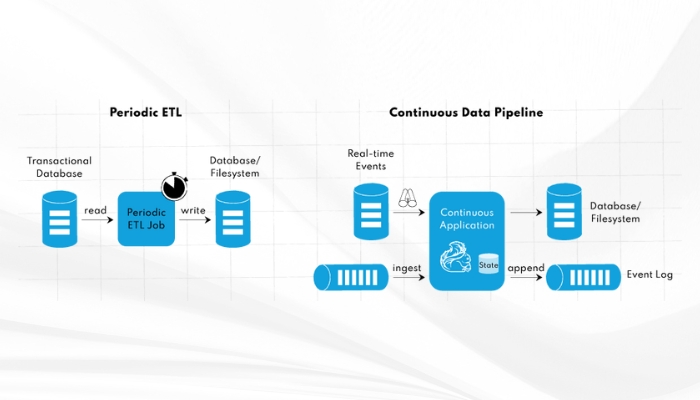
- Dòng dữ liệu liên tục: Flink thay thế các công việc ETL theo chu kỳ. Bằng cách xử lý dữ liệu liên tục, giúp chuyển đổi và làm giàu dữ liệu theo thời gian thực.
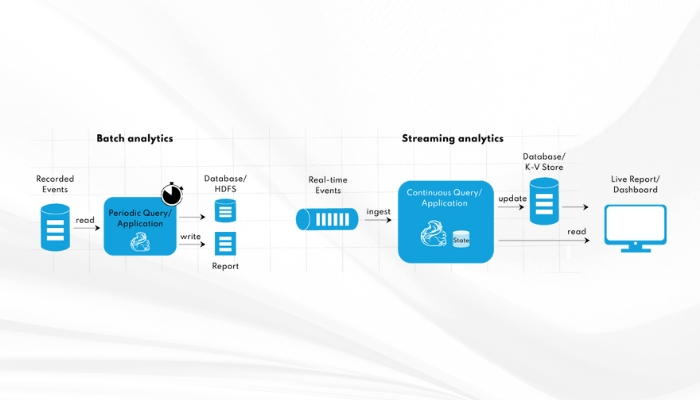
- Phân tích dữ liệu thời gian thực: Flink xử lý dữ liệu với độ trễ thấp, lý tưởng cho việc phân tích dữ liệu ngay lập tức. Ví dụ: giám sát khách hàng, phát hiện xâm nhập mạng.
- Học máy: FlinkML cung cấp các thuật toán học máy phân tán, hỗ trợ đào tạo mô hình với dữ liệu lớn và tích hợp với các framework học sâu.
- Xử lý đồ thị: Gelly là thư viện xử lý và phân tích đồ thị, giúp thực hiện các phép toán đồ thị trên dữ liệu lớn.
Hệ sinh thái của Apache Flink gồm những gì?
Flink không chỉ là một công cụ xử lý dữ liệu mà còn là một hệ sinh thái với nhiều công cụ và thư viện khác nhau. Những công cụ quan trọng nhất bao gồm:
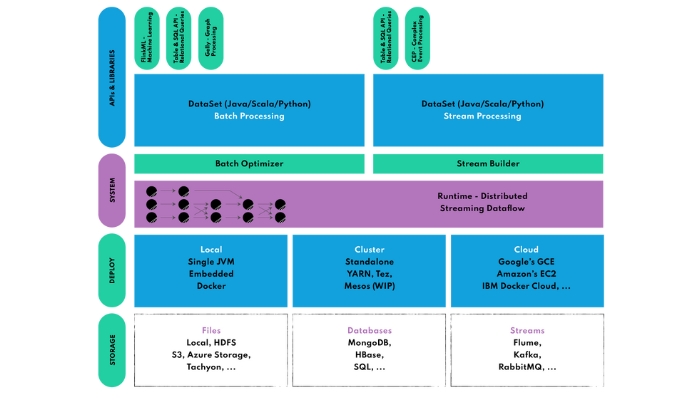
DataSet APIs
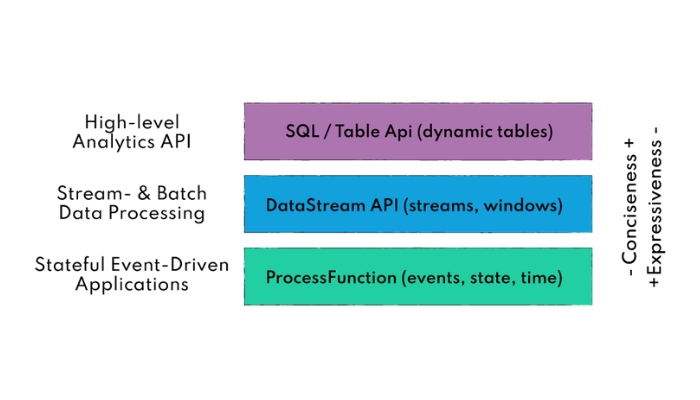
DataSet API là API chính của Flink dùng để xử lý dữ liệu theo lô (batch). Nó hỗ trợ các thao tác như map, reduce, (outer) join, co-group và lặp lại (iterate).
DataStream APIs
DataStream API được sử dụng để xử lý dữ liệu luồng (streaming data), tức là dữ liệu không giới hạn và liên tục. Nó cho phép người dùng định nghĩa các thao tác tùy chỉnh trên các sự kiện đến. Chẳng hạn như cửa sổ (windowing), biến đổi từng bản ghi (record-at-a-time transformations), và làm phong phú sự kiện bằng cách truy vấn cơ sở dữ liệu bên ngoài.
Complex Event Processing (CEP)
Thư viện Complex Event Processing (CEP) của Flink giúp người dùng xác định các mẫu sự kiện sử dụng biểu thức chính quy hoặc máy trạng thái (state machine). Thư viện CEP được tích hợp với DataStream API, giúp nhận diện mẫu sự kiện theo thời gian thực. CEP có thể ứng dụng trong phát hiện bất thường trong mạng, cảnh báo theo quy tắc, giám sát quy trình và phát hiện gian lận.
SQL & Table API
Flink cung cấp các API SQL và Table để thực hiện các truy vấn quan hệ, giúp người dùng xử lý dữ liệu dòng và dữ liệu theo lô theo cách đơn giản. Người dùng có thể viết truy vấn SQL, sử dụng API Table và thao tác dữ liệu theo các sơ đồ bảng để xây dựng các pipeline biến đổi dữ liệu phức tạp một cách dễ dàng.
Gelly
Gelly là thư viện xử lý và phân tích đồ thị chạy trên DataSet API. Nó cung cấp các thuật toán tích hợp sẵn như lan truyền nhãn (label propagation), đếm tam giác (triangle enumeration) và xếp hạng trang (page rank), đồng thời hỗ trợ API đồ thị giúp người dùng dễ dàng xây dựng các thuật toán đồ thị tùy chỉnh.
FlinkML
FlinkML là thư viện các thuật toán học máy phân tán, chạy trên DataSet API. Thư viện này cung cấp một cách tiếp cận thống nhất để áp dụng các kỹ thuật học có giám sát và không có giám sát. Như hồi quy tuyến tính (linear regression), hồi quy logistic (logistic regression), cây quyết định (decision trees), phân cụm k-means, LDA,…. FlinkML cũng có một framework học sâu thử nghiệm để xây dựng mạng nơ-ron (sử dụng TensorFlow).
Flink, Kafka và Spark, khi nào nên sử dụng?
Kafka Streams là thư viện phổ biến cho xử lý luồng dữ liệu. Đặc biệt khi dữ liệu vào và ra được lưu trữ trong Kafka. Nó tận dụng các lợi ích của Kafka một cách tự nhiên. ksqlDB giúp đơn giản hóa việc xử lý luồng bằng cách sử dụng SQL trên Kafka Streams, mang đến một cách tiếp cận dễ dàng hơn cho người dùng.
Người dùng Kafka và khách hàng Confluent thường chọn Apache Flink để xử lý luồng phức tạp vì một số lý do. Ví dụ, khi xử lý luồng phức tạp, trạng thái trung gian có thể rất lớn và Kafka không phải lúc nào cũng phù hợp để lưu trữ trạng thái này. Ngoài ra, Flink có thể xử lý các luồng dữ liệu từ nhiều Kafka cluster ở các vị trí khác nhau và kết hợp với các luồng ngoài Kafka.

Mặc dù Flink là một hệ thống phân tán riêng biệt với những yêu cầu phức tạp. Song vẫn chưa rõ khi nào việc sử dụng Flink mang lại lợi ích vượt trội so với các công nghệ khác như Kafka Streams hay Apache Spark.
Lời kết
Như vậy, với nội dung trên, các bạn đã hiểu Apache Flink là gì? Những ưu nhược điểm cũng như khi nào nên sử dụng. LANIT rất hy vọng đã đem lại kiến thức hữu ích tới bạn. Nếu bạn đang tìm kiếm một công cụ xử lý luồng mạnh mẽ với độ trễ thấp có thể xử lý tất cả các tác vụ của bạn. Apache Flink chắc chắn là một lựa chọn đáng xem xét.
Mọi người cùng tìm hiểu: