Rag là gì?
RAG (Retrieval-Augmented Generation) là một kỹ thuật trong AI kết hợp giữa truy xuất thông tin (retrieval) và mô hình sinh (generation). Mục đích để tạo ra câu trả lời chính xác, giàu ngữ cảnh hơn.
RAG giúp AI trở nên thông minh và đáng tin cậy hơn bằng cách kết hợp dữ liệu thực tế với sức mạnh của mô hình sinh. RAG gồm hai thành phần chính:
- Mô-đun truy xuất (Retrieval Module): Tìm kiếm tài liệu liên quan từ nguồn dữ liệu lớn bằng các kỹ thuật. Như Dense Passage Retrieval (DPR) để xác định nội dung phù hợp nhất.
- Mô-đun sinh (Generation Module): Sử dụng mô hình ngôn ngữ như GPT hoặc BART. Nhằm tổng hợp thông tin từ tài liệu truy xuất, tạo ra câu trả lời tự nhiên và đầy đủ.

>>> Xem thêm: LLM là gì? Thành Phần Chính và Cách Thức Hoạt Động
Lịch sử hình thành của Rag
RAG (Retrieval-Augmented Generation) không phải là một khái niệm hoàn toàn mới. Nó có nguồn gốc từ những nghiên cứu về truy xuất thông tin (IR – Information Retrieval) từ những năm 1970.
Giai đoạn đầu: Những năm 1970 – 1990
Các nhà khoa học bắt đầu phát triển hệ thống trả lời câu hỏi (QA – Question Answering) dựa trên xử lý ngôn ngữ tự nhiên (NLP). Ban đầu, các hệ thống này chỉ hoạt động trong những lĩnh vực cụ thể như thể thao hay y học.
Bước tiến trong thập niên 1990 – 2000
Công nghệ truy xuất thông tin trở nên phổ biến hơn nhờ các công cụ tìm kiếm trên internet. Ask Jeeves (nay là Ask.com) ra mắt vào giữa những năm 1990. Cho phép người dùng đặt câu hỏi trực tiếp và nhận câu trả lời thay vì chỉ tìm kiếm theo từ khóa.
Sự phát triển mạnh mẽ từ 2010 đến nay
IBM Watson gây tiếng vang khi đánh bại hai nhà vô địch trong gameshow Jeopardy! vào năm 2011. Chiến thắng này đánh dấu bước nhảy vọt của AI trong truy xuất và xử lý thông tin.
Đến những năm 2020, với sự phát triển của mô hình ngôn ngữ lớn (LLM – Large Language Models) như GPT, kỹ thuật RAG ra đời. Nhằm cải thiện độ chính xác của AI bằng cách kết hợp truy xuất thông tin thời gian thực với khả năng sinh nội dung.

Nguyên lý hoạt động của Rag là gì?
RAG hoạt động bằng cách kết hợp truy xuất thông tin và mô hình sinh ngôn ngữ để tạo ra câu trả lời chính xác hơn. Trước tiên, hệ thống thu thập và xử lý dữ liệu từ nhiều nguồn, sau đó chuyển đổi chúng thành vector và lưu trữ trong cơ sở dữ liệu vector. Khi nhận được truy vấn, mô-đun truy xuất sẽ tìm kiếm và trích xuất các đoạn nội dung liên quan từ kho dữ liệu này. Cuối cùng, mô hình sinh ngôn ngữ sử dụng thông tin được truy xuất, kết hợp với kiến thức sẵn có. Sau đó tạo ra phản hồi phù hợp với bối cảnh, giúp câu trả lời chính xác và giàu ý nghĩa hơn.
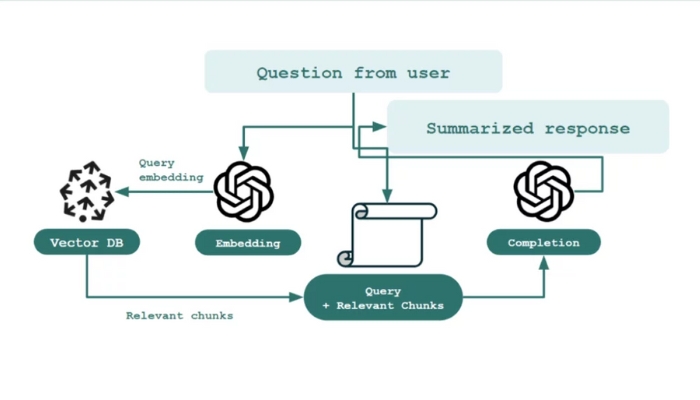
Rag cải thiện LLM như thế nào?
RAG giúp cải thiện LLM bằng cách bổ sung dữ liệu cụ thể từ nguồn bên ngoài, giúp mô hình tạo ra câu trả lời chính xác và phù hợp hơn. Thay vì chỉ dựa vào dữ liệu huấn luyện cố định, RAG truy xuất thông tin từ kho dữ liệu tùy chỉnh, giúp chatbot hoặc trợ lý ảo cung cấp phản hồi cập nhật và chính xác hơn.
Điều này khắc phục hạn chế của LLM như thiếu thông tin chi tiết, tạo ra nội dung sai lệch (hallucination) và phản hồi chung chung. Nhờ đó, RAG mang lại trải nghiệm cá nhân hóa và đáng tin cậy hơn cho người dùng.
Vì sao Rag lại quan trọng
Nếu đã hiểu Rag là gì thì chắc chắn bạn sẽ biết tầm quan trọng của kỹ thuật này. Nổi bật có thể kể đến:
- RAG giúp LLM tránh lỗi “ảo giác” (hallucination) bằng cách truy xuất dữ liệu thực tế từ nguồn đáng tin cậy.
- Cập nhật thông tin mới nhất, theo thời gian thực
- Cho phép tích hợp dữ liệu riêng của tổ chức, giúp phản hồi phù hợp với từng doanh nghiệp và khách hàng.
- Cải thiện độ tin cậy của AI
- Hữu ích cho nhiều lĩnh vực, nâng cao trải nghiệm người dùng

Những ưu và nhược điểm của Rag
Bất cứ kỹ thuật nào cũng đều có mặt hạn chế và Rag không phải ngoại lệ.
Về ưu điểm:
- Không cần đào tạo lại toàn bộ mô hình khi cần bổ sung dữ liệu
- Tiết kiệm chi phí, thời gian
- Dễ tùy chỉnh theo nhu cầu, không bị giới hạn
- Cung cấp câu trả lời mới nhất, không lỗi thời
Về nhược điểm:
- Việc truy xuất dữ liệu trước khi sinh nội dung có thể khiến thời gian phản hồi chậm hơn so với LLM thuần túy.
- Yêu cầu hệ thống lưu trữ mạnh
- Việc xây dựng và tích hợp RAG đòi hỏi hiểu biết về NLP, truy xuất thông tin và cơ sở dữ liệu vector.
- Nếu không quản lý tốt, RAG có thể truy xuất và cung cấp thông tin nhạy cảm ngoài ý muốn.
- Nếu không chọn lọc kỹ, AI có thể lấy thông tin không chính xác.

Quy trình của Rag là gì?
Vậy quy trình của Rag thường diễn ra như thế nào? Dưới đây là các bước chi tiết để triển khai một hệ thống RAG hiệu quả:
Bước 1: Thu thập và chuẩn bị dữ liệu
Đầu tiên, cần thu thập tất cả dữ liệu liên quan phục vụ cho hệ thống. Dữ liệu này có thể đến từ nhiều nguồn khác nhau như tài liệu nội bộ, hướng dẫn sử dụng, cơ sở tri thức doanh nghiệp, danh sách câu hỏi thường gặp (FAQ) hoặc các báo cáo nghiên cứu. Dữ liệu phải được làm sạch để loại bỏ trùng lặp, sai sót và đảm bảo tính nhất quán trước khi đưa vào hệ thống.
Bước 2: Chia nhỏ và tổ chức dữ liệu
Dữ liệu thu thập được sẽ được phân chia thành các đoạn nhỏ hơn, thường được gọi là “chunks”, để dễ dàng xử lý và truy xuất. Quá trình này giúp hệ thống tập trung vào những thông tin quan trọng thay vì phân tích toàn bộ tài liệu một cách không hiệu quả. Việc phân đoạn cũng giúp cải thiện tốc độ tìm kiếm và đảm bảo phản hồi phù hợp với từng câu hỏi cụ thể.
Bước 3: Nhúng dữ liệu vào không gian vector
Mỗi đoạn dữ liệu sẽ được chuyển đổi thành biểu diễn số dưới dạng vector thông qua một mô hình nhúng (embedding model). Quá trình này giúp hệ thống hiểu được ý nghĩa ngữ cảnh của văn bản, thay vì chỉ so sánh từ khóa đơn thuần. Các vector này được lưu trữ trong cơ sở dữ liệu vector, cho phép tìm kiếm thông tin một cách hiệu quả dựa trên ngữ nghĩa.
Bước 4: Xử lý truy vấn người dùng
Khi người dùng đặt câu hỏi, truy vấn của họ cũng được chuyển thành vector nhúng bằng cùng một mô hình embedding. Sau đó, hệ thống sử dụng các phương pháp đo độ tương đồng như độ tương đồng cosin hoặc khoảng cách Euclid để tìm kiếm các đoạn văn bản có liên quan nhất trong cơ sở dữ liệu vector. Những kết quả này sẽ được lấy ra để cung cấp thêm ngữ cảnh cho LLM.
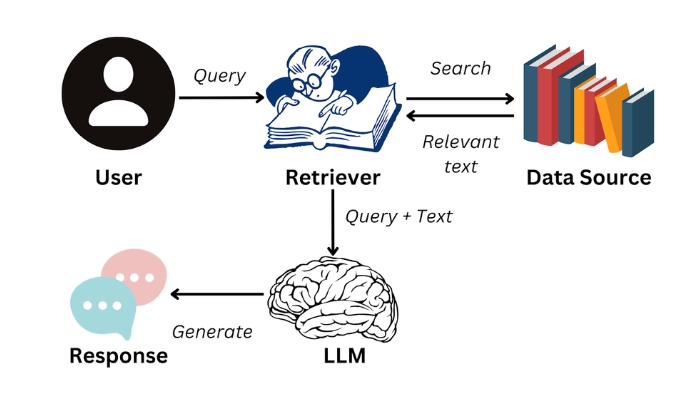
Bước 5: Tạo phản hồi bằng LLM
Các đoạn văn bản phù hợp được truy xuất từ cơ sở dữ liệu vector sẽ được kết hợp với truy vấn của người dùng và đưa vào mô hình ngôn ngữ lớn. LLM sẽ sử dụng những thông tin này để tạo ra câu trả lời chính xác, phù hợp với bối cảnh câu hỏi. Nhờ đó, hệ thống có thể cung cấp phản hồi chi tiết, đúng trọng tâm và đáng tin cậy hơn so với một mô hình ngôn ngữ đơn thuần.
Bước 6: Kiểm tra và tối ưu phản hồi
Sau khi tạo phản hồi, hệ thống có thể triển khai thêm các cơ chế kiểm tra chất lượng như đánh giá tính chính xác, tính nhất quán và mức độ phù hợp với truy vấn. Các phản hồi cũng có thể được tối ưu bằng cách tinh chỉnh mô hình nhúng hoặc cập nhật dữ liệu trong cơ sở tri thức. Mục đích để cải thiện hiệu suất theo thời gian.
Những ứng dụng thực tế của Rag
RAG (Retrieval-Augmented Generation) không chỉ cải thiện khả năng xử lý ngôn ngữ tự nhiên mà còn mở rộng phạm vi ứng dụng trong nhiều lĩnh vực khác nhau. Dưới đây là một số ứng dụng quan trọng của RAG trong thực tế:
- Chatbot & Trợ Lý Ảo: RAG giúp chatbot như ChatGPT, Google Bard cung cấp phản hồi chính xác và cập nhật hơn.
- Công Cụ Tìm Kiếm Thông Minh: RAG nâng cấp hệ thống tìm kiếm bằng cách hiểu ngữ cảnh thay vì chỉ so khớp từ khóa. Đồng thời cung cấp câu trả lời chính xác hơn thông qua truy xuất và tổng hợp nội dung từ nhiều nguồn.
- Hệ Thống Hỏi Đáp Chuyên Sâu: RAG hỗ trợ bác sĩ, luật sư và chuyên gia tài chính ra quyết định hiệu quả hơn. Bằng cách truy xuất và cung cấp thông tin chính xác từ các tài liệu chuyên ngành
- Viết Báo Cáo & Tổng Hợp Thông Tin: Tổng hợp tin tức, báo cáo thị trường và tài liệu nghiên cứu từ nhiều nguồn. Hỗ trợ nhà báo, doanh nghiệp và chuyên gia nghiên cứu làm việc nhanh chóng và hiệu quả.

Điểm khác biệt giữa GPT-4 so với Rag là gì?
GPT-4 mạnh về ngôn ngữ tự nhiên nhưng có giới hạn về dữ liệu cập nhật. Trong khi RAG giúp cải thiện độ chính xác bằng cách kết hợp truy xuất dữ liệu. Điểm khác biệt rõ giữa hai AI này có thể kể đến:
| Tiêu chí | GPT-4 | RAG (Retrieval-Augmented Generation) |
| Nguồn dữ liệu | Dựa vào dữ liệu đã huấn luyện, không cập nhật theo thời gian thực | Truy xuất dữ liệu từ nguồn bên ngoài, đảm bảo thông tin cập nhật |
| Độ chính xác | Có thể mắc lỗi hoặc tạo ra thông tin sai (hallucination) | Giảm lỗi nhờ truy xuất dữ liệu thực tế |
| Khả năng mở rộng | Hạn chế bởi dữ liệu huấn luyện | Mở rộng kiến thức không giới hạn nhờ kết hợp với cơ sở dữ liệu bên ngoài |
| Ứng dụng | Tổng quát, phù hợp cho hội thoại chung | Phù hợp với các lĩnh vực cần thông tin chính xác như y tế, pháp lý, tài chính |
| Cách hoạt động | Dự đoán từ tiếp theo dựa trên dữ liệu huấn luyện | Truy xuất thông tin từ nguồn bên ngoài trước khi tạo phản hồi |
Tương lai của Rag và AI
RAG không chỉ cải thiện khả năng xử lý thông tin của AI mà còn góp phần thúc đẩy sự phát triển của AI trong tương lai.
Phát triển trong các hệ thống AI tự học (Self-learning AI)
RAG có tiềm năng trở thành một phần quan trọng trong các hệ thống AI tự học, giúp AI không chỉ phản hồi dựa trên dữ liệu đã huấn luyện mà còn có thể truy xuất và cập nhật kiến thức từ các nguồn bên ngoài theo thời gian thực. Điều này giúp AI trở nên thông minh hơn, giảm thiểu thông tin lỗi thời và nâng cao khả năng thích ứng với môi trường mới.
Tích hợp vào AI doanh nghiệp để tối ưu hóa quản lý tri thức
Các doanh nghiệp ngày càng sử dụng AI để quản lý và khai thác dữ liệu hiệu quả. Khi tích hợp RAG vào hệ thống AI doanh nghiệp, tổ chức có thể truy cập thông tin chính xác từ các tài liệu nội bộ, cơ sở dữ liệu khách hàng và báo cáo kinh doanh theo thời gian thực. Điều này giúp cải thiện quy trình ra quyết định, nâng cao năng suất và tối ưu hóa việc quản lý tri thức trong doanh nghiệp.
Ứng dụng mạnh mẽ trong giáo dục và nghiên cứu khoa học
Trong lĩnh vực giáo dục, RAG có thể giúp tạo ra các trợ lý học tập thông minh, cung cấp tài liệu cập nhật và giải đáp câu hỏi theo cách chính xác, cá nhân hóa. Đối với nghiên cứu khoa học, RAG hỗ trợ truy xuất thông tin từ hàng triệu bài báo khoa học, giúp các nhà nghiên cứu dễ dàng tiếp cận dữ liệu mới nhất, thúc đẩy quá trình phát triển tri thức và sáng tạo.

Câu hỏi thường gặp
RAG có thể kết hợp với các mô hình AI nào?
RAG có thể được tích hợp với nhiều mô hình AI hiện đại, bao gồm:
- GPT-4, Llama, Claude: Cải thiện độ chính xác khi sinh văn bản.
- BERT, T5: Hỗ trợ tìm kiếm thông tin ngữ nghĩa.
- Vector Databases (FAISS, Pinecone, Weaviate): Tối ưu hóa khả năng truy xuất dữ liệu nhanh chóng.
Làm thế nào để đánh giá hiệu suất của RAG?
Để đánh giá hiệu suất, có thể sử dụng các tiêu chí sau:
- Độ chính xác của kết quả truy xuất: Kiểm tra xem thông tin lấy được có phù hợp với truy vấn không.
- Mức độ liên quan của câu trả lời: Đánh giá phản hồi của AI có đúng với ngữ cảnh hay không.
- Tốc độ phản hồi: Đảm bảo hệ thống có thể truy xuất và tạo nội dung nhanh chóng.
- Tỷ lệ lỗi (hallucination rate): Kiểm tra xem AI có tạo ra thông tin sai lệch không.
Có công cụ nào giúp xây dựng hệ thống RAG không?
Nhiều công cụ và nền tảng hỗ trợ triển khai RAG, bao gồm:
- LangChain: Framework phổ biến để tích hợp truy xuất và sinh văn bản.
- Haystack (deepset AI): Công cụ giúp xây dựng hệ thống hỏi đáp với RAG.
- OpenAI API + Vector Database: Kết hợp OpenAI GPT-4 với cơ sở dữ liệu như Pinecone, Weaviate.
- Elasticsearch: Hỗ trợ tìm kiếm thông tin mạnh mẽ.
RAG có thể thay thế hoàn toàn con người không?
Không. RAG chỉ là công cụ hỗ trợ, không thể thay thế chuyên gia trong các lĩnh vực yêu cầu phân tích sâu và tư duy phức tạp. Tuy nhiên, nó có thể giúp giảm tải công việc, tiết kiệm thời gian và nâng cao hiệu suất làm việc.
Lời kết
Sau khi đã hiểu Rag là gì thì bạn có công nhận rằng Rag là một kỹ thuật quan trọng trong AI không? Trong tương lai AI ngày càng phát triển thì buộc ta ngày phải nâng cấp kỹ thuật Rag. Nếu bạn còn thắc mắc ở đâu hãy để lại bình luận để LANIT hỗ trợ giải đáp bạn nhanh nhất nhé!
Tham khảo thêm các bài viết cùng chủ đề dưới đây: