Thuật toán CNN là gì?
Convolutional Neural Network (CNN) hay còn gọi là ConvNet, là một loại mạng nơ-ron tích tụ được sử dụng phổ biến trong lĩnh vực xử lý hình ảnh. Thuật toán CNN là một phần quan trọng của Deep Learning – tập hợp các thuật toán nhằm xây dựng mô hình dữ liệu trừu tượng thông qua việc sử dụng nhiều lớp xử lý cấu trúc phức tạp.
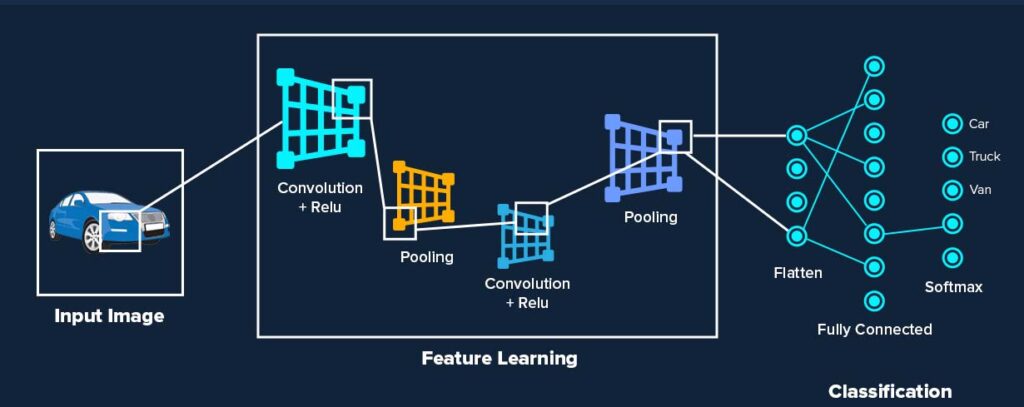
CNN hoạt động dựa trên dữ liệu ảnh và được sử dụng rộng rãi trong các ứng dụng như nhận dạng hình ảnh và khuôn mặt. Thuật toán CNN hiện được tích hợp vào các nền tảng mạng phổ biến như Facebook và Google,… Thuật toán CNN nhận đầu vào dưới dạng một mảng hai chiều và xử lý trực tiếp trên hình ảnh, giúp nó trích xuất các đặc trưng quan trọng từ dữ liệu hình ảnh một cách hiệu quả.
Về phần kỹ thuật, thuật toán CNN là mô hình được sử dụng trong quá trình training và kiểm tra dữ liệu hình ảnh. Mỗi hình ảnh đầu vào sẽ đi qua một chuỗi các bước, bao gồm các lớp tích chập với các bộ lọc (Kernel), sau đó là lớp kết nối đầy đủ và cuối cùng áp dụng hàm Softmax để phân loại đối tượng. Kết quả phân loại sẽ là một giá trị xác suất nằm trong khoảng từ 0 đến 1.
Các lớp cơ bản của thuật toán CNN
#1. Convolution Layer (Lớp tích chập)
Convolution Layer là lớp đầu tiên để lấy các đặc điểm từ hình ảnh ban đầu. Nó giữ lại các mối quan hệ giữa các pixel bằng cách xem xét các tính năng của hình ảnh thông qua việc sử dụng các ô vuông nhỏ từ dữ liệu gốc. Đây là một phép tính với hai thành phần đầu vào, là ma trận hình ảnh ban đầu và một bộ lọc hoặc hạt nhân.

Ví dụ: Xem xét ma trận 5 x 5 với giá trị pixel 0 và 1 với ma trận bộ lọc 3 x 3.

Lớp Convolution (tích chập) của ma trận hình ảnh 5 x 5 sẽ nhân với bộ lọc 3 x 3 được gọi là Feature Map.

Với sự kết hợp giữa một hình ảnh và nhiều bộ lọc thì hình ảnh có thể được làm mờ hoặc sắc nét hay phát hiện cạnh. Hình ảnh tích chập khác nhau khi áp dụng những kernel khác nhau.
#2. Stride (Bước nhảy)
Stride chính là số pixel luôn thay đổi trên ma trận đầu vào. Khi stride là 1, ta di chuyển kernel 1 pixel, nếu stride là 2 thì di chuyển kernel 2 pixel,…

#3. Padding (Đường viền)
Trong trường hợp kernel không tương xứng với hình ảnh đầu vào thì có thể lựa chọn 1 trong 2 cách sau:
- Chèn thêm số 0 vào 4 đường biên hình ảnh
- Cắt bớt những điểm không phù hợp với kernel
#4. ReLU (Hàm phi tuyến)
Rectified Linear Unit hay ReLU là một hàm phi tuyến. Đầu ra là: f(x) = max (0,x). ReLU có thể giới thiệu tính phi tuyến trong ConvNet. Dữ liệu mà chúng ta tìm hiểu thường là các giá trị tuyến tính không âm.
Một số hà phi tuyến khác có thể kể đến như: sigmoid, tanh cũng có thể thay thế cho ReLU nhưng ReLU thường được ưu tiên sử dụng bởi hiệu suất tốt.

#5. Pooling Layer (Lớp gộp)
Khi hình ảnh quá lớn thì lớp Pooling sẽ giúp giảm bớt số lượng tham số. Không gian Pooling lấy mẫu con giúp giảm kích thước map nhưng vẫn giữ lại được những thông tin quan trọng. Có nhiều loại Pooling khác nhau như: Sum Pooling, Max Pooling và Average Pooling.
Trong đó Max Pooling thường lấy tổng trung bình hoặc lấy phần tử lớn nhất từ ma trận. Tổng tất cả phần tử trong đối tượng map được gọi là Sum Pooling.

Cấu trúc mạng của thuật toán CNN
Mạng CNN là một trong các lớp Convolution chồng lên nhau. Nó sử dụng các hàm kích hoạt phi tuyến (như ReLU và tanh) để tạo ra thông tin trừu tượng và kích hoạt trọng số trong node. Các lớp này cung cấp tính bất biến và tính kết hợp, nhằm giúp mạng hiểu được đối tượng theo nhiều góc độ khác nhau.
Pooling layer giúp làm cho mạng không nhạy cảm đối với việc dịch chuyển, co giãn và quay hình ảnh. Còn tính kết hợp cục bộ là kết quả của các lớp Convolution liên kết với nhau. Mỗi lớp tiếp theo dựa trên kết quả của lớp Convolution trước đó và đảm bảo kết nối cục bộ hiệu quả nhất. Ngoài ra, có các lớp khác như lớp pooling/subsampling, được sử dụng để lọc thông tin quan trọng và loại bỏ thông tin nhiễu.
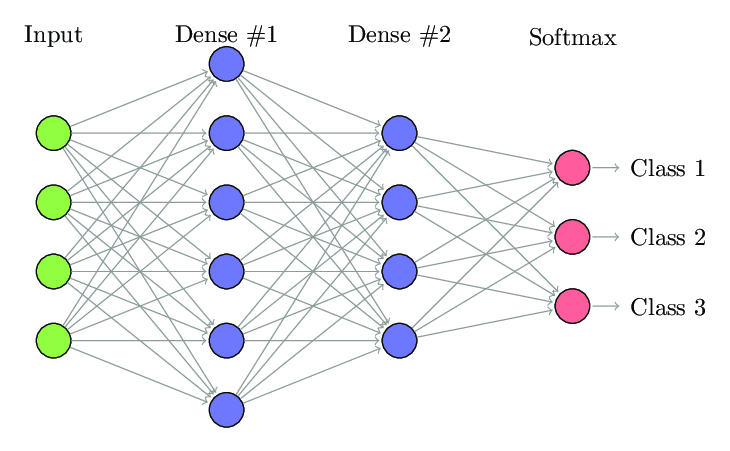
Trong quá trình huấn luyện, thuật toán CNN sẽ tự động học cách nhận biết các đặc điểm thông qua việc sử dụng các bộ lọc. Quá trình này tương tự việc bộ não con người nhận diện các đối tượng trong thế giới thực.
Thuật toán CNN gồm 3 phần chính, đó là:
- Local receptive field (trường cục bộ): Trường cục bộ có nhiệm vụ chia dữ liệu thành các phần nhỏ để xác định vùng quan trọng và tạo ra các vùng ảnh có giá trị cao nhất.
- Shared weights and bias (trọng số và bias chia sẻ): Trong mạng CNN, trọng số và bias chia sẻ giúp giảm thiểu số lượng tham số cần sử dụng. Mỗi lớp convolution bao gồm nhiều feature map khác nhau, và mỗi feature map có khả năng nhận biết một số đặc điểm trong ảnh.
- Pooling layer (lớp tổng hợp): Lớp tổng hợp là bước cuối cùng trong quá trình tính toán và quét qua các lớp. Nhiệm vụ của nó là đơn giản hóa dữ liệu đầu ra, loại bỏ thông tin không cần thiết và tối ưu hóa kết quả cuối cùng. Điều này giúp đảm bảo rằng người dùng nhận được kết quả đáng tin cậy và phù hợp với yêu cầu của họ.
Cách chọn tham số khi sử dụng thuật toán CNN
Để điều chỉnh tham số cho CNN một cách tốt nhất, bạn nên xem xét các yếu tố sau:
- Convolution layer (lớp tích chập): Số lượng lớp tích chập ảnh. Thông thường, sử dụng từ 3 đến 5 lớp có thể mang lại kết quả mong muốn. Số lượng lớp nhiều hơn có thể cải thiện hiệu suất, nhưng cần cân nhắc để tránh tốn nhiều tài nguyên.
- Filter size (kích thước filter): Filter thường có kích thước 3×3 hoặc 5×5. Kích thước này có thể được điều chỉnh để phù hợp với bộ dữ liệu cụ thể.
- Pooling size (kích thước pooling): Kích thước pooling thường là 2×2 cho hình ảnh tiêu chuẩn. Đối với hình ảnh lớn hơn, bạn có thể sử dụng kích thước 4×4.
- Số lần train và test: Thực hiện nhiều lần train và test để tối ưu hóa các tham số. Điều này giúp mô hình trở nên “thông minh” và hiệu quả hơn.
Kết luận
Mong rằng bài viết “Tìm hiểu thuật toán CNN là gì” đã giúp bạn nắm được các kiến thức cơ bản về CNN đồng thời biết được cách chọn tham số cho CNN một cách chuẩn nhất. Nếu như có bất kì thắc mắc nào xin đừng chần chừ mà bình luận ngay phía dưới để LANIT giải đáp giúp bạn nhé!










